
Agentic AI Security Scoping Matrix: Inspired by AWS Work

AWS recently launched the Agentic AI Security Scoping Matrix, a framework designed to help organizations securely deploy autonomous AI systems. The AWS framework categorizes AI systems into four scopes based on agency and autonomy levels:
Scope 1 (No Agency): Human-initiated, read-only operations with fixed workflow paths
Scope 2 (Prescribed Agency): Human approval required for all actions with limited autonomous capabilities
Scope 3 (Supervised Agency): Autonomous execution after human initiation with optional human guidance
Scope 4 (Full Agency): Fully autonomous, self-initiating systems with strategic human oversight
Each scope comes with tailored security controls across six critical dimensions: Identity Context, Data Protection, Audit & Logging, Agent & FM Controls, Agency Perimeters, and Orchestration. This progressive framework enables organizations to assess their agentic AI use cases, identify security gaps, and implement appropriate controls for their level of autonomy.
Two Critical Improvements Needed
While the AWS framework provides valuable guidance, there are two areas where refinement would enhance its precision and practical applicability:
1. Scope 1 Terminology: “No Agency” Misrepresents Read-Only Capabilities
The classification of Scope 1 as “No Agency” is misleading. Read-only agents with human-in-the-loop (HITL) still possess decision authority and data access privileges, which constitutes a form of agency. These agents autonomously:
Formulate queries and search strategies
Decide which data sources to access
Determine how to aggregate and present information
Make contextual decisions about relevance and prioritization
This creates a distinct threat surface including:
Data exfiltration risks: Unauthorized aggregation of sensitive information
Privacy violations: Accessing personally identifiable information (PII) beyond intended scope
Information disclosure: Revealing confidential data through inference or pattern analysis
Reconnaissance attacks: Systematic probing of data structures for exploitation
The security controls required for Scope 1 agents—data classification, access logging, query boundary enforcement, DLP policies, and semantic access controls—demonstrate that these systems do exercise agency, albeit limited to read operations.
Recommendation: Rename Scope 1 from “No Agency” to “Read-Only Limited Agency” to accurately reflect the security considerations and decision-making capabilities these agents possess.
2. Conflating Agency with Read/Write Capabilities
The current framework’s single-axis progression from Scope 1 to Scope 4 conflates two distinct dimensions: data operation capabilities (read vs. write) and autonomy levels (human oversight vs. autonomous operation). This creates ambiguity in risk assessment:
A read-only agent with high autonomy (continuous monitoring, self-initiated queries) poses fundamentally different risks than a write-capable agent requiring human approval for each action
The framework doesn’t clearly distinguish between an agent that can write but requires approval versus one that can only read but operates fully autonomously
Organizations may struggle to properly scope agents that have asymmetric capabilities (e.g., broad read access but restricted write permissions)
This conflation makes it difficult to:
Implement granular security controls tailored to specific risk profiles
Progress incrementally by adding capabilities or increasing autonomy independently
Communicate precise security requirements to development and operations teams
Proposing a Multi-Dimensional Security Framework
To address these limitations, I propose a two-dimensional matrix that separates data operation capabilities from autonomy levels, creating a more nuanced and precise security framework. The following is Nano Banana generated image to illustrate the idea. But seriously, please read the actual text and tables which are created by me.
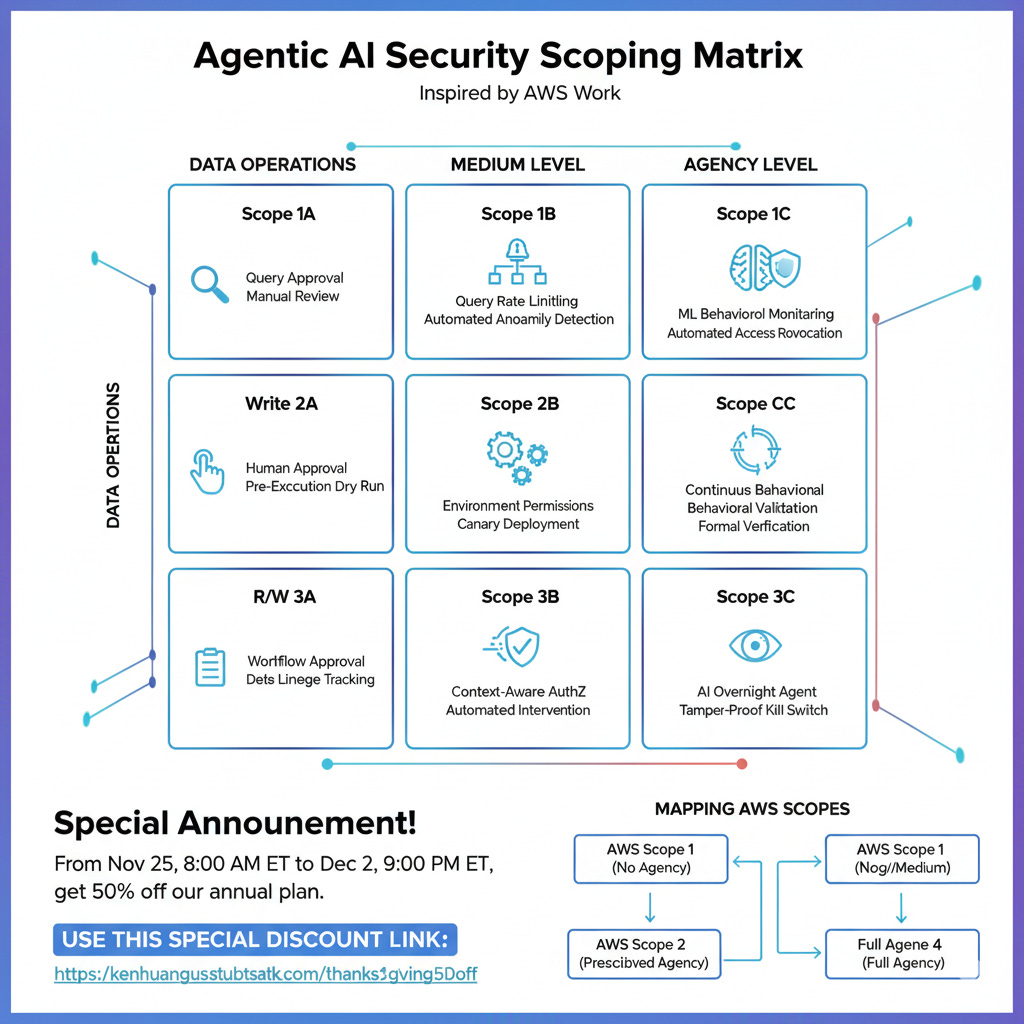
This image is generated by Nano Banana
We are getting more formal in all text below…
Terminology Clarification
To align with AWS’s conceptual framework while simplifying communication, this matrix uses terminology as follows:
Data Operations (Vertical Axis): Corresponds to AWS’s concept of “agency” - the scope of actions an AI system is permitted to take (read, write, or both)
Agency Level (Horizontal Axis): Corresponds to AWS’s concept of “autonomy” - the degree of independent decision-making without human intervention
This simplification maintains AWS’s important distinction between what agents can do and how independently they operate, while providing clearer communication for security teams implementing these controls.
The Two-Dimensional Approach
Rather than a single-axis progression, this framework uses:
Dimension 1: Data Operations (Vertical Axis)
Read-Only: Agent can query, retrieve, and analyze data but cannot modify systems
Write-Only: Agent can create/modify/delete data but operates on predefined inputs
Read/Write: Agent can both discover information and take actions based on findings
Dimension 2: Agency Level (Horizontal Axis)
Low Agency: Human-in-the-loop for most/all decisions, predefined operational boundaries
Medium Agency: Supervised autonomy with human oversight for high-risk operations only
High Agency: Fully autonomous with post-action review and monitoring
This creates a 3x3 matrix with nine distinct security scopes, each with tailored risk profiles and security controls:
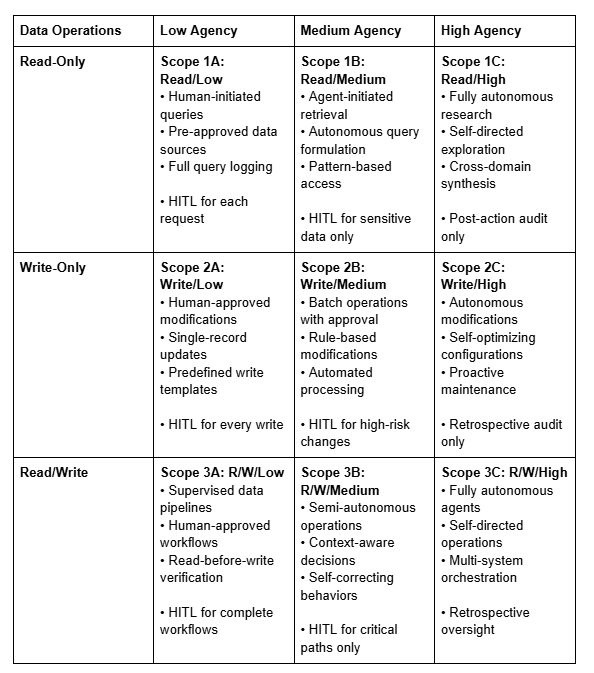
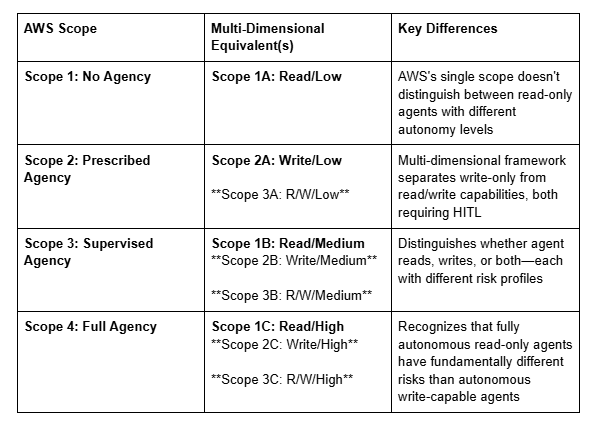
Mapping AWS Scopes to Multi-Dimensional Framework
To help organizations transition between frameworks, here’s how AWS’s four scopes map to this multi-dimensional approach:
Use Case Examples
To demonstrate practical application of the multi-dimensional framework, here are three real-world examples showing how different agents map to specific scopes:
Example 1: Financial Fraud Detection Agent
Current State: Scope 1C (Read/High Agency)
This agent continuously monitors transaction patterns across the organization’s payment systems, autonomously analyzing millions of transactions daily without human initiation.
Capabilities:
Self-initiated investigation of anomalous patterns
Cross-domain data synthesis (transaction history, customer behavior, merchant patterns)
Autonomous pattern recognition and risk scoring
Real-time alerting to security operations center
Why Scope 1C?
Read-Only: Cannot block transactions or modify account settings, only flags for human review
High Agency: Operates continuously, self-directs investigations, no human approval needed for queries
Key Security Controls:
ML-based behavioral monitoring to detect anomalous agent query patterns
Query rate limiting: Maximum 100,000 queries per hour to prevent data harvesting
Data aggregation monitoring: Alerts when single session accesses >50,000 customer records
Automated access revocation when suspicious patterns detected
Comprehensive audit trails with reasoning chain capture
Risk Profile: Primary concerns are mass data exfiltration, sophisticated inference attacks leading to privacy violations, and persistent reconnaissance that could map entire data architecture.
Why Not Scope 2A (Write/Low)? Although Scope 2A requires human approval (seemingly more restrictive), a write-capable agent poses fundamentally different risks. Even with HITL, a compromised write agent could execute approved-but-malicious modifications. The fraud detection agent’s read-only nature makes it inherently lower risk despite high autonomy.
Example 2: DevOps Configuration Management Agent
Current State: Scope 2B (Write/Medium Agency)
This agent manages infrastructure configurations across development, staging, and production environments with context-aware approval workflows.
Capabilities:
Batch configuration updates across multiple systems
Rule-based optimization of resource allocations
Automated scaling decisions based on load patterns
Self-initiated configuration drift detection and remediation
Why Scope 2B?
Write-Only: Can modify system configurations but doesn’t need to read sensitive application data
Medium Agency: Auto-approves changes in dev/test environments, requires HITL for production changes
Key Security Controls:
Approval workflow enforcement: Cryptographically signed approval tokens for production changes
Environment-based permission boundaries: Full autonomy in dev/test, HITL required for production
Canary deployment patterns: 5% rollout → validation → full deployment
Automated rollback triggers: Revert changes if error rates exceed 0.1% threshold
Change validation: Pre-execution dry runs and impact analysis
Time-bounded elevated access: Production write permissions expire after 4 hours
Risk Profile: Primary concerns are cascading configuration corruption across environments, privilege escalation through configuration tampering, and unauthorized production modifications.
Why Not Scope 1B (Read/Medium) or Scope 3B (R/W/Medium)? Scope 1B wouldn’t allow the necessary configuration modifications. Scope 3B would be appropriate if the agent also needed to read sensitive application data to make configuration decisions. However, this agent operates on infrastructure metrics and configuration files only, making write-only designation appropriate and reducing attack surface.
Example 3: Autonomous Incident Response Agent
Current State: Scope 3C (R/W/High Agency)
This agent provides 24/7 security monitoring with autonomous threat detection, investigation, and containment capabilities.
Capabilities:
Self-initiated threat hunting across network, endpoint, and cloud environments
Autonomous investigation: queries logs, analyzes binaries, correlates indicators
Autonomous containment actions: network isolation, account suspension, process termination
Multi-agent coordination with SIEM, EDR, and SOAR platforms
Continuous learning from threat intelligence feeds and past incidents
Why Scope 3C?
Read/Write: Must both investigate threats (read) and take containment actions (write)
High Agency: Operates autonomously during security incidents without waiting for human approval
Key Security Controls:
AI-powered security monitoring with dedicated oversight agent monitoring the IR agent itself
Behavioral baselines: ML models trained on 90 days of normal IR agent operations
Automated intervention: Secondary agent validates IR agent decisions before execution
Action correlation analysis: Tracks cascading effects of containment actions
Formal verification: Mathematical proof that agent actions preserve system safety properties
Tamper-proof human override: Hardware-based kill switch accessible to security leadership
Circuit breakers: Automatic scope reduction to Scope 3B if confidence scores drop below 85%
Comprehensive forensics: Immutable audit logs with reasoning chain and decision rationale
Risk Profile: Primary concerns are autonomous attack chain execution if agent is compromised, lateral movement through authorized access, self-propagating malicious modifications, and potential for agent to disable its own oversight mechanisms.
Why Scope 3C and Not Lower? Cyber incidents require sub-second response times. Waiting for human approval (Scope 3A or 3B) could allow attackers to achieve objectives before containment. However, this high-risk deployment requires the most sophisticated security controls, including AI-powered oversight of the agent itself.
Progressive Deployment Path: This organization started with Scope 1B (read-only threat detection with autonomous investigation but human-executed response), progressed to Scope 3B (autonomous response for known threat patterns, HITL for novel threats), and finally reached Scope 3C after 18 months of validation and control maturation.
Comprehensive Security Control Matrix
The following six tables decompose a comprehensive agentic AI security framework across nine operational scopes. Each scope is defined by two dimensions: permission level (Read-only, Write-only, or Read-Write) and risk exposure (Low, Medium, or High), creating nine distinct security postures from Scope 1A (Read/Low) to Scope 3C (Read-Write/High). The six security dimensions covered are:
Table 1A: Identity Context (AuthN/AuthZ) Controls - Defines authentication and authorization mechanisms that verify who or what is accessing systems and what permissions they possess.
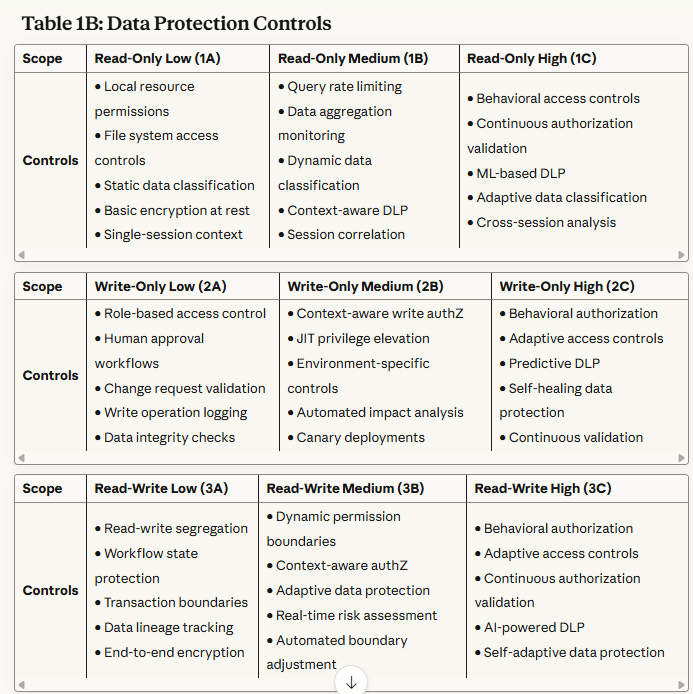
Table 1B: Data Protection Controls - Specifies how sensitive information is classified, encrypted, and protected during access and modification operations.
Table 1C: Audit & Logging Controls - Details the monitoring, tracking, and forensic capabilities needed to maintain visibility into agent activities and detect anomalies.
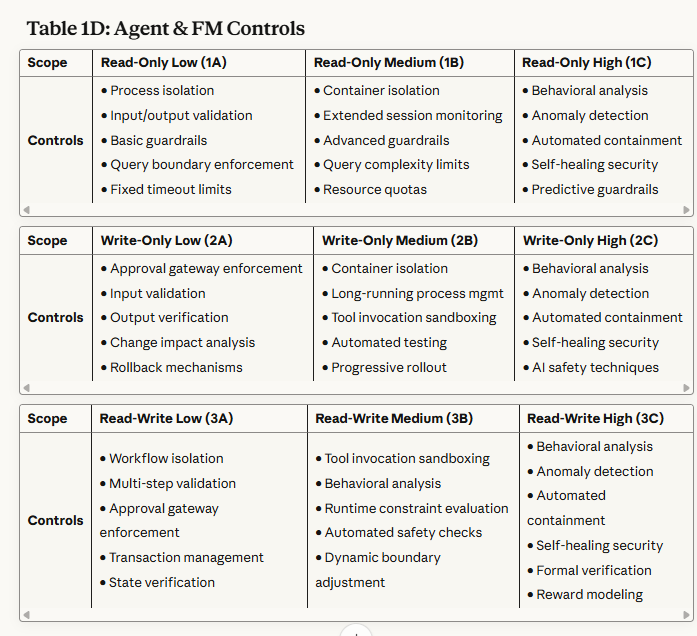
Table 1D: Agent & FM Controls - Addresses containment, guardrails, and safety mechanisms specific to AI agents and foundation models.
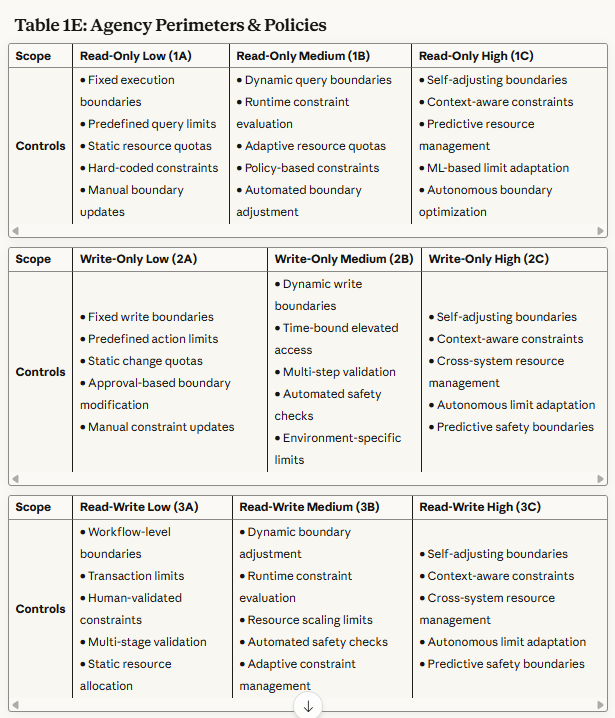
Table 1E: Agency Perimeters & Policies - Establishes the operational boundaries within which agents can act autonomously and how those boundaries adapt dynamically.
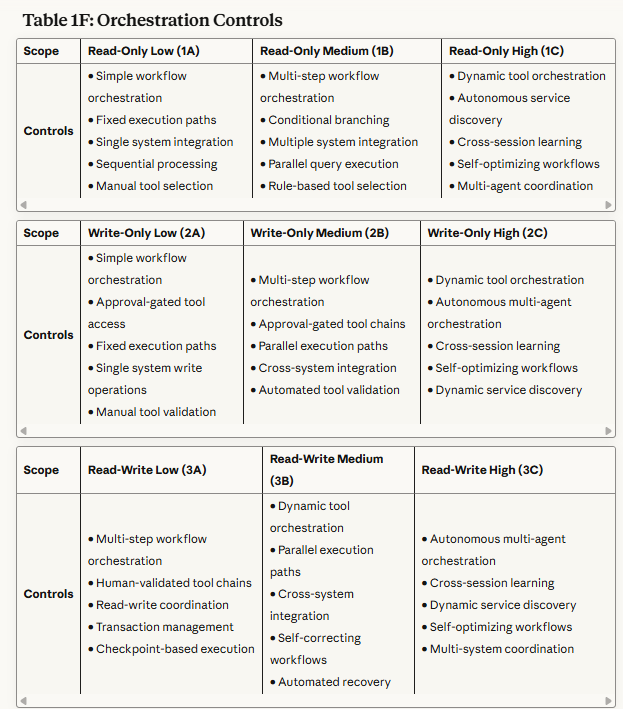
Table 1F: Orchestration Controls - Describes how agents coordinate actions across multiple tools, services, and systems while maintaining security.
Each table shows a progression from basic, manually-managed controls in low-risk scenarios to sophisticated, self-adaptive security mechanisms in high-risk environments where agents operate with greater autonomy.
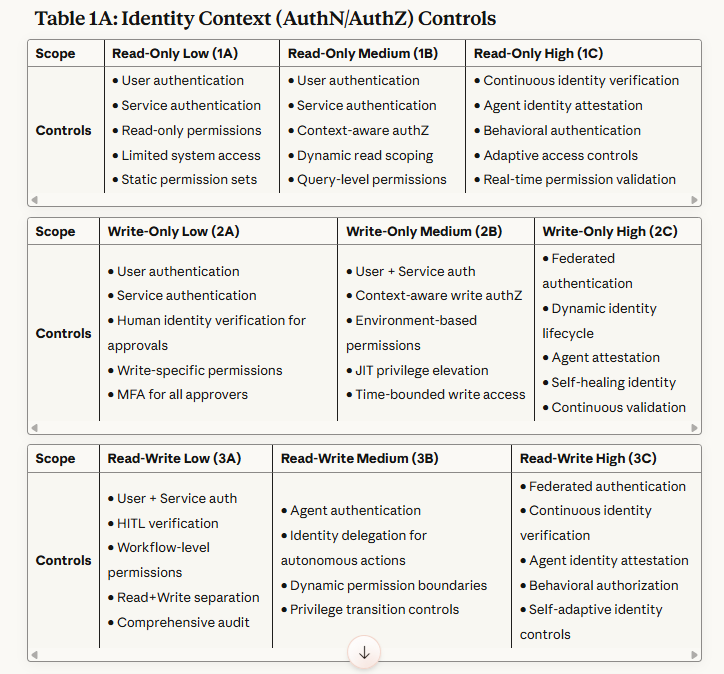

Implementation Notes by Scope Category
Read-Only Scopes (1A, 1B, 1C): Primary focus on preventing data exfiltration and privacy violations. Controls emphasize query boundary enforcement, aggregation limits, and behavioral monitoring.
Write-Only Scopes (2A, 2B, 2C): Primary focus on preventing unauthorized modifications and ensuring change integrity. Controls emphasize approval workflows, rollback mechanisms, and impact analysis.
Read/Write Scopes (3A, 3B, 3C): Primary focus on preventing autonomous attack chains and maintaining operational alignment. Controls emphasize end-to-end workflow monitoring, behavioral analysis, and formal verification.
Key Architectural Patterns
Successful agentic deployments using the multi-dimensional framework share common patterns that balance autonomy with control:
1. Progressive Deployment Strategy
Organizations can progress through the matrix in two independent dimensions:
Horizontal Progression (Increasing Autonomy):
Start: Low Agency (HITL for all operations)
Progress: Medium Agency (HITL for high-risk operations only)
Mature: High Agency (post-action review and monitoring)
Vertical Progression (Adding Capabilities):
Start: Read-Only (information gathering and analysis)
Progress: Write-Only (executing predefined modifications)
Mature: Read/Write (autonomous investigation and response)
Example Deployment Path:
Month 0-3: Deploy at Scope 1A (Read/Low) - establish baseline security posture
Month 3-6: Progress to Scope 1B (Read/Medium) - validate autonomous query patterns
Month 6-12: Progress to Scope 1C (Read/High) - demonstrate continuous operation safety
Month 12-18: Advance to Scope 3B (R/W/Medium) - add write capabilities with oversight
Month 18-24: Advance to Scope 3C (R/W/High) - achieve full autonomous operation
This dual-axis progression allows organizations to increase either autonomy or capabilities based on their security maturity, risk tolerance, and demonstrated control effectiveness.
2. Layered Security Architecture
Implement defense-in-depth with security controls at multiple levels across all nine scopes:
Network Layer:
Microsegmentation to limit agent lateral movement
Encrypted communications between agent components
Network-based behavioral monitoring
Application Layer:
Input validation and output filtering
API rate limiting and throttling
Session management and state protection
Agent Layer:
Model guardrails and prompt injection defense
Reasoning chain validation
Tool access controls and sandboxing
Data Layer:
Encryption at rest and in transit
Fine-grained access controls
Data classification and DLP
Critical Consideration: Address identity and authorization concerns rigorously to prevent the confused deputy problem, where agents with elevated privileges could be manipulated to perform actions on behalf of users with lesser permissions.
3. Continuous Validation Loops
Establish automated systems that continuously verify agent behavior against expected patterns:
Behavioral Baselines:
Establish normal operation patterns during low-risk scopes (1A, 2A, 3A)
Use machine learning to model expected query patterns, write frequencies, and resource consumption
Define confidence thresholds for acceptable deviations (typically 3σ for statistical anomalies)
Real-Time Monitoring:
Continuous comparison of agent actions against baselines
Automated alerting when anomalies detected
Escalation procedures for security operations teams
Validation Checkpoints:
Scope 1A-1C: Validate query patterns, data access volumes, aggregation behaviors
Scope 2A-2C: Validate change frequencies, impact scope, rollback effectiveness
Scope 3A-3C: Validate end-to-end workflow integrity, reasoning chain logic, multi-agent coordination
4. Human Oversight Integration
Even in highly autonomous systems (High Agency), maintain meaningful human oversight through strategic mechanisms:
Shifting Oversight Focus:
Low Agency Scopes (1A, 2A, 3A): High human involvement in operational decisions (HITL for each action)
Medium Agency Scopes (1B, 2B, 3B): Moderate human involvement (HITL for high-risk operations)
High Agency Scopes (1C, 2C, 3C): Low operational involvement but HIGH strategic oversight
Strategic Oversight for High Agency:
Regular review of audit logs and behavioral patterns
Validation of alignment with organizational objectives
Assessment and adjustment of security controls
Implementation of more sophisticated monitoring and containment
Periodic testing and red teaming of agent systems
Human oversight doesn’t decrease from Scope 1 to Scope 3 or from Low to High Agency—it shifts from operational approval to strategic governance and control validation.
5. Graceful Degradation Pathways
Design systems to automatically reduce autonomy levels when security events are detected:
Automated Degradation Matrix:
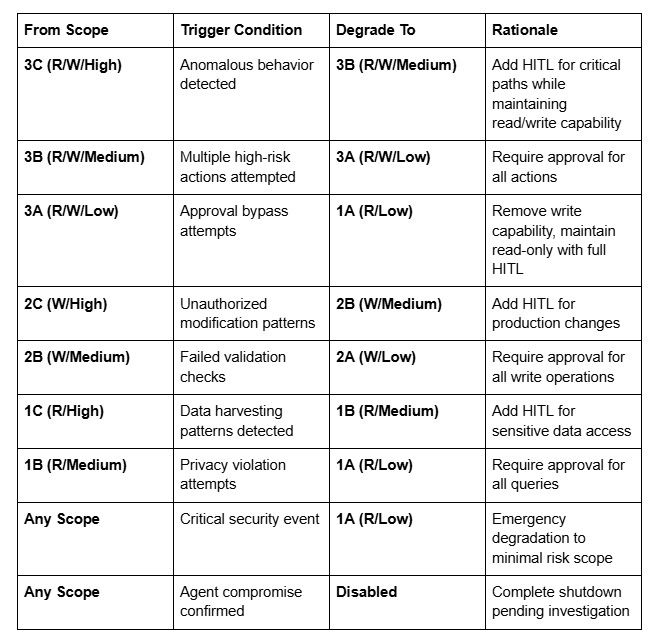
Detection Mechanisms:
Behavioral anomaly detection (deviation from established baselines)
Rule-based triggers (specific dangerous actions attempted)
Confidence score monitoring (agent’s self-assessed confidence drops below threshold)
External threat intelligence (known attack patterns detected)
Manual operator intervention (security team identifies concerning behavior)
Automated Response Actions:
Trigger detected → Log event with full context
Assess severity using risk scoring model
Initiate degradation to appropriate lower scope
Alert security operations team
Generate incident report with reasoning chain
Await human review before scope restoration
Restoration Criteria:
Root cause analysis completed and documented
Security controls validated and enhanced as needed
Comprehensive testing in lower scope demonstrates safe operation
Security leadership approval obtained
Monitoring enhanced for early detection of recurrence
6. Risk-Based Scope Selection
Organizations should select the appropriate scope based on systematic risk assessment:
Risk Scoring Model:
Data Operation Risk: Read-Only = 1, Write-Only = 2, Read/Write = 3
Agency Level Risk: Low = 1, Medium = 2, High = 3
Total Risk Score = Data Operation × Agency Level
Risk Tolerance Mapping:
Risk Score 1-2 (Scopes 1A, 1B, 2A): Acceptable for most use cases with standard controls
Risk Score 3-4 (Scopes 1C, 2B, 3A): Requires enhanced monitoring and mature security program
Risk Score 6 (Scopes 2C, 3B): Requires advanced security capabilities and leadership approval
Risk Score 9 (Scope 3C): Requires comprehensive security program, AI-powered oversight, and continuous validation
Use Case Factors:
Criticality of systems accessed
Sensitivity of data involved
Regulatory compliance requirements
Business impact of agent errors
Organizational security maturity
Availability of security resources for monitoring and response
Risk Profiles and Mitigation Strategies
Read-Only Agents (Scopes 1A, 1B, 1C)
Primary Risks:
Data exfiltration through authorized queries
Privacy violations via inference attacks
Information disclosure through aggregation
Reconnaissance mapping of data architecture
Unauthorized data correlation across systems
Scope-Specific Controls:
Scope 1A (Read/Low):
Query approval workflows with human review
Pre-approved data source whitelist
Single-query session limits
Daily query volume caps
Manual audit log review
Scope 1B (Read/Medium):
Query rate limiting (e.g., 100 queries/minute)
Data aggregation monitoring (alert on >10K records/session)
Semantic access controls with policy enforcement
Automated anomaly detection for query patterns
Real-time alerting to SOC for suspicious activity
Scope 1C (Read/High):
ML-based behavioral monitoring with 3σ deviation thresholds
Automated access revocation triggers
Threat intelligence integration
AI-powered anomaly detection
Continuous authorization validation with risk-based scoring
Write-Only Agents (Scopes 2A, 2B, 2C)
Primary Risks:
Data corruption through unauthorized modifications
Integrity violations and cascading failures
Privilege escalation through configuration tampering
Unauthorized production changes
Irreversible system modifications
Scope-Specific Controls:
Scope 2A (Write/Low):
Human approval required for every write operation
Multi-factor authentication for approvers
Cryptographically signed approval decisions
Pre-execution dry runs and validation
Mandatory rollback capability for all changes
Scope 2B (Write/Medium):
Environment-based permission boundaries (auto-approve dev/test, HITL for production)
Canary deployment patterns (5% → validation → 100%)
Automated impact analysis before execution
Time-bounded elevated access (4-hour expiration)
Progressive rollout with automated rollback triggers
Scope 2C (Write/High):
Continuous behavioral validation with ML models
Automated circuit breakers (revert if error rate >0.1%)
Predictive monitoring with anomaly forecasting
Self-healing rollback mechanisms
Formal verification of change safety properties
Read/Write Agents (Scopes 3A, 3B, 3C)
Primary Risks:
Autonomous attack chains (read to identify, write to exploit)
Lateral movement through authorized access
Self-propagating modifications across systems
Advanced persistent threats leveraging agent privileges
Agent compromise enabling sophisticated attacks
Scope-Specific Controls:
Scope 3A (R/W/Low):
Workflow-level human approval for complete operations
Read-write operation segregation and validation
Transaction boundaries with ACID properties
Data lineage tracking for audit
End-to-end workflow monitoring
Scope 3B (R/W/Medium):
Context-aware authorization with dynamic risk assessment
Behavior-based detection using ML models
Action correlation analysis across read and write operations
Automated intervention for high-risk action sequences
Self-correcting behaviors with human override
Scope 3C (R/W/High):
AI-powered security monitoring with dedicated oversight agent
Comprehensive autonomous threat detection
Formal verification of operational safety
Multi-layered behavioral analysis
Tamper-proof human override mechanisms
Reward modeling for AI safety
Continuous alignment validation
Advantages of the Multi-Dimensional Framework
1. More Precise Risk Assessment
A read-only agent with high autonomy (Scope 1C) has fundamentally different risks than a write-capable agent with low autonomy (Scope 2A):
Scope 1C risks: Mass data harvesting, sophisticated inference attacks, persistent reconnaissance
Scope 2A risks: Data corruption, unauthorized modifications, integrity violations
The single-axis AWS framework would categorize both scenarios similarly, obscuring these critical distinctions.
2. Granular Security Controls
Each of the nine scopes has specific risk profiles requiring tailored security controls:
Scope 1C: ML-based anomaly detection for autonomous reconnaissance patterns
Scope 2A: Approval workflow security and change validation
Scope 3C: Comprehensive autonomous threat detection with formal verification
Organizations can implement precisely the controls needed for their specific deployment rather than over-securing low-risk use cases or under-securing high-risk ones.
3. Progressive Deployment Flexibility
Organizations can progress in two independent dimensions:
Horizontal progression: Increase autonomy (Low → Medium → High) while maintaining read-only capability
Vertical progression: Add write capability while maintaining HITL oversight
This flexibility allows incremental risk acceptance aligned with security maturity, rather than forcing organizations to jump from read-only/HITL to read-write/autonomous in a single progression.
4. Better Alignment with Real-World Use Cases
Most enterprise agents fall clearly into one of the nine categories:
Fraud detection systems: Typically Scope 1C (autonomous monitoring, read-only)
Configuration management: Typically Scope 2B (write capability, HITL for production)
Incident response: Typically Scope 3C (full autonomy, read-write required)
This precision makes the framework more practical for architecture decisions, security assessments, and compliance documentation.
5. Clearer Communication
Development, security, and operations teams can precisely specify:
What the agent can do (read, write, or both)
How autonomously it operates (low, medium, or high)
Which specific controls are required for that scope
This clarity reduces miscommunication, improves security posture, and accelerates deployment timelines.
Implementation Guidance
Organizations adopting this framework should follow these implementation steps:
Phase 1: Assessment
Inventory Current Agents:
Document all existing agentic AI deployments
Classify each agent’s current data operations (read, write, read/write)
Assess current autonomy level (low, medium, high)
Map each agent to one of the nine scopes
Gap Analysis:
Compare current security controls against scope requirements (Table 1)
Identify missing controls across six security dimensions
Assess organizational security maturity
Document risk exposure for each agent
Risk Prioritization:
Calculate risk scores for each agent (Data Operation × Agency Level)
Prioritize remediation based on risk scores and business criticality
Identify quick wins (agents operating at higher scope than necessary)
Phase 2: Control Implementation
Baseline Security:
Implement foundational controls required for all scopes:
Basic authentication and authorization
Comprehensive audit logging
Input/output validation
Encryption at rest and in transit
Scope-Specific Controls:
Implement controls from Table 1 for each agent’s target scope
Start with highest-risk agents (Scopes 2C, 3B, 3C)
Deploy monitoring and alerting infrastructure
Establish baseline behavioral patterns
Testing and Validation:
Conduct security testing for each scope
Validate graceful degradation pathways
Test human override mechanisms
Perform red team exercises
Phase 3: Progressive Deployment
Start with Lower Scopes:
New agents begin at Scope 1A regardless of target scope
Establish 30-90 days of baseline operation
Validate security controls effectiveness
Document lessons learned
Gradual Progression:
Progress horizontally (increase autonomy) OR vertically (add capabilities)
Never progress in both dimensions simultaneously
Require security leadership approval for each progression
Maintain ability to degrade to previous scope
Continuous Monitoring:
Implement real-time behavioral monitoring
Establish SOC playbooks for agent security events
Regular review of audit logs and anomaly reports
Quarterly security assessments
Phase 4: Governance and Optimization (Ongoing)
Establish Governance:
Define roles and responsibilities for agent security
Create approval processes for scope changes
Establish incident response procedures
Document compliance and audit requirements
Continuous Improvement:
Regular security control effectiveness reviews
Update behavioral baselines quarterly
Incorporate threat intelligence into monitoring
Refine graceful degradation triggers based on operational experience
Training and Awareness:
Train development teams on secure agentic AI development
Train security teams on agent-specific threats
Train operations teams on monitoring and response
Executive awareness of agentic AI risks and governance
Conclusion
The AWS Agentic AI Security Scoping Matrix provides an essential foundation for securing autonomous AI systems. However, by addressing the “No Agency” misnomer and separating data operation capabilities from autonomy levels, we can create a more precise and practical framework.
The proposed multi-dimensional approach:
Recognizes that read-only agents exercise meaningful agency
Distinguishes between what agents can do and how autonomously they operate
Provides nine distinct security scopes with tailored risk profiles and controls
Enables more flexible and incremental deployment strategies
Aligns better with real-world enterprise use cases
As the industry moves toward standardizing agentic AI security frameworks—through initiatives like OWASP AIVSS, CSA’s AI Safety working groups, and CoSAI—these refinements will be critical for helping organizations deploy autonomous AI systems securely and confidently.
The goal is not to replace the AWS framework but to enhance it, providing organizations with the precision needed to implement appropriate security controls for their specific agentic AI deployments. As we collectively build the future of autonomous AI systems, these definitional refinements and multi-dimensional thinking will help ensure we do so safely and responsibly.
Thanks for read the whole article, now I have good news for you!
From Nov 25, 8:00 AM ET to Dec 2, 9:00 PM ET, if you subscribe to our annual plan, you get 50% off.
Use this special discount Link when it is still available: https://kenhuangus.substack.com/thanksgiving50off
About the Author
Ken Huang is an AI security expert who serves as co-chair of the Cloud Security Alliance’s AI Safety working group and Chair of the OWASP AI Vulnerability Severity Scoring (AIVSS) project. He specializes in developing industry standards for agentic AI security and has contributed to multiple AI security frameworks and publications.
Agree that read-only ≠ no agency and that separating capability (read/write) from autonomy is essential for real-world risk assessment. The two-dimensional model adds much-needed clarity for securing agentic systems in practice.
BTW I was building agents and deploying AI in 2018 for systems that the world relies on. LLMs just make my job easier.