
Designing Agentic AI Systems with the ORCHIDEAS Framework

A secure-by-construction approach to nine-pillar agentic AI design, integrated with the Cloud Security Alliance MAESTRO threat modeling framework
By Ken Huang, Fellow and Co-Chair of AI Safety Working Group at Cloud Security Alliance
Introduction: Security as a Structural Property
Most security failures in software systems come from treating security as something added on top of an otherwise-complete design. A team builds the application, then adds authentication; ships the feature, then writes the audit log; designs the architecture, then performs a penetration test. The defects this approach produces are not usually exotic — they are predictable consequences of asking security to retrofit a structure that was not built for it.
Agentic AI systems make this approach untenable. The principal making decisions is probabilistic, partially opaque, and capable of being steered by adversarial inputs that look indistinguishable from legitimate ones. The boundary between data and instruction is porous. The system’s behavior emerges from the interaction of components in ways that cannot be fully predicted from any single component’s specification. A bolt-on security model — runtime checks layered onto an otherwise-trusting architecture — produces a system whose security properties depend on the perfection of those checks, and the checks are never perfect.
The alternative is secure by construction: design the system so that the security properties you want are invariants of the architecture itself. Violating those invariants requires explicitly bypassing the structure, not merely neglecting to add a check. The agent cannot act without an attested intent token, because the action interface only accepts calls bound to one. The model cannot be invoked directly, because all calls flow through a gateway by construction. Tool authority cannot expand across handoffs, because capability tokens are attenuated by construction. Context content from untrusted sources cannot enter privileged context slots, because the segregation is structural. The threat model still applies — but it applies to the architecture’s invariants rather than to a runtime-checking surface that depends on every check firing correctly.
This document presents ORCHIDEAS, a nine-pillar design framework for agentic AI systems built on the secure-by-construction premise, integrated with the Cloud Security Alliance’s MAESTRO threat modeling framework. ORCHIDEAS organizes the design space; MAESTRO organizes the threat space. Together they let a team build systems whose security properties are structural rather than aspirational.
The framework name is a mnemonic rather than a construction sequence. The design sequence is Autonomy, Identity & Intent, Data & Memory Governance, Context, Runtime, Human Oversight & Override, Observability, Eval/Environment/Ecosystem, and Scalability. The same nine pillars are remembered as ORCHIDEAS, whose letter order emphasizes the complete set rather than the build order. ORCHIDEAS is Spanish for “orchids,” a fitting metaphor for systems whose health depends on every environmental condition being right and whose ecosystem is intricate enough to require deliberate cultivation.
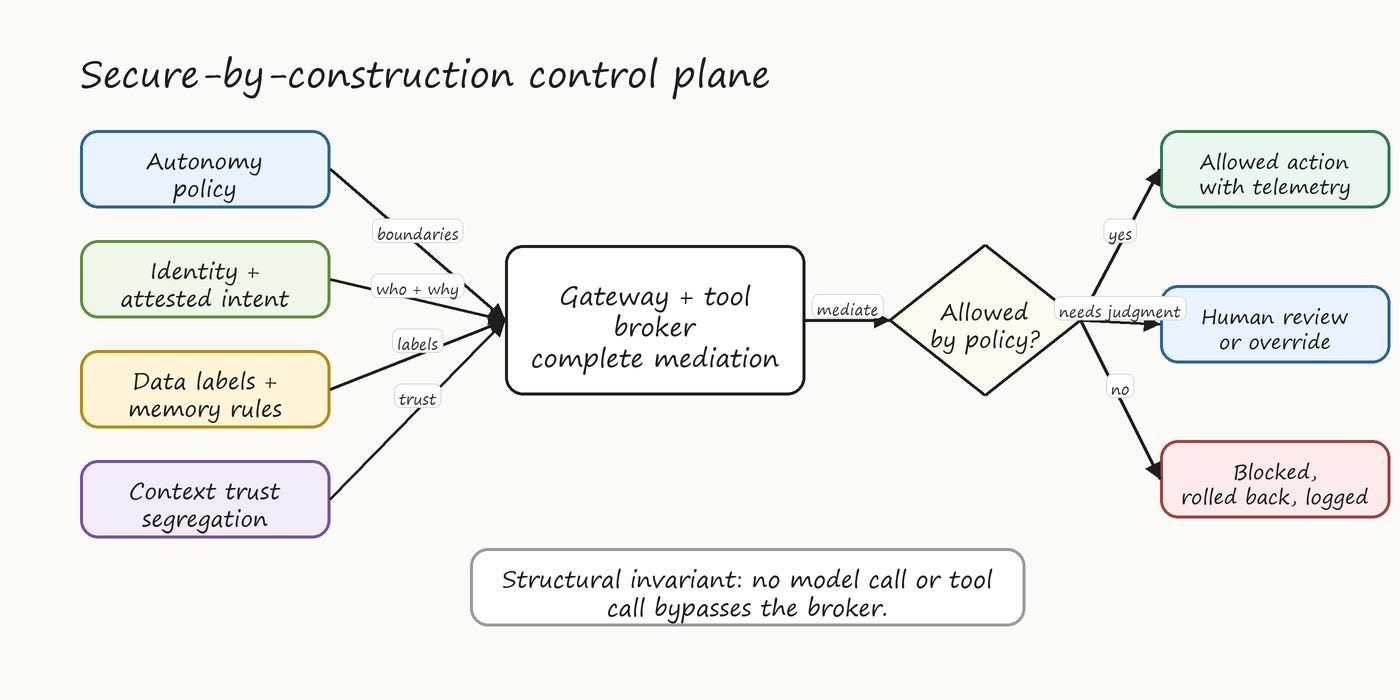
Figure 1. Secure-by-construction control plane showing how autonomy policy, identity, data governance, and context controls converge at the gateway and tool broker.
The Engineering Disciplines That Ground ORCHIDEAS
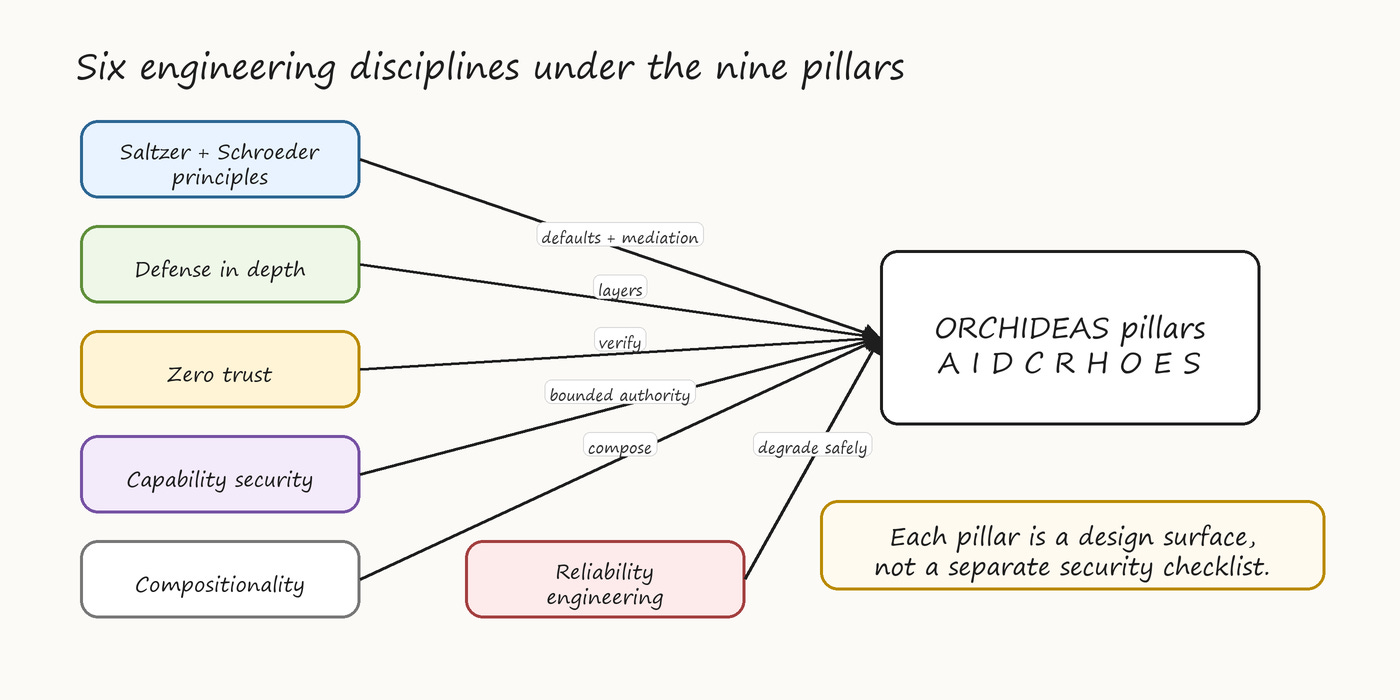
Before walking through the pillars, it helps to name the engineering disciplines they embody. Each pillar is not an arbitrary collection of concerns but an application of well-established principles to the specific surfaces that agentic AI presents. Six disciplines run through the entire framework.
The first is the Saltzer and Schroeder security principles, articulated in 1975 and still the bedrock of security engineering. Economy of mechanism (keep designs simple enough to reason about), fail-safe defaults (default-deny rather than default-allow), complete mediation (every access checked, no shortcuts), open design (security does not depend on secrecy of the mechanism), separation of privilege (require more than one condition for sensitive operations), least privilege (each component gets only the authority it needs), least common mechanism (minimize shared mechanism between principals), and psychological acceptability (controls users will actually use). These principles map directly onto agentic system design: complete mediation becomes the LLM gateway and tool broker pattern; least privilege becomes attenuated capability tokens; fail-safe defaults becomes the default-deny posture at autonomy boundaries.
The second is defense in depth: no single control prevents the failure mode you fear most. The intent of layering controls is not redundancy for its own sake but the assumption that any individual control will sometimes fail. A robust agentic system has prompt injection defenses at the input filter, at the context assembly, at the model conditioning, at the tool broker, at the action confirmation, and at the observability layer. The attack must defeat all of them to succeed, while the defender must succeed at only one to catch it.
The third is zero trust, applied to internal architecture as much as to external boundaries. The agent does not trust its own context content unconditionally. The orchestrator does not trust the agent’s stated intent unconditionally. The tool broker does not trust the agent’s tool selection unconditionally. The MCP server does not trust the calling agent’s identity claim unconditionally. Trust is established through cryptographic attestation and bounded by policy, not assumed from network location or prior interaction.
The fourth is capability-based security. Authority in the system is conveyed through unforgeable tokens that name exactly what may be done. An agent that holds a capability token for “read customer record 12345 within intent task-xyz for the next 60 seconds” cannot, by construction, read customer record 67890, or read 12345 after the TTL, or read 12345 under a different intent. The capability defines the authority; possession is sufficient; nothing more is granted. This contrasts with ambient authority models where principals possess broad permissions and rely on runtime checks to narrow them — a model that fails predictably under prompt injection.
The fifth is compositionality: secure components must compose into secure systems, with the security properties of the whole derivable from the properties of the parts. This is the discipline that gives “secure by construction” its meaning. Without compositionality, every interaction between components is its own threat model; with compositionality, the architectural choices ensure that combinations of secure components do not produce insecure emergent behavior. Compositionality requires clear trust boundaries, well-typed interfaces, and explicit reasoning about what each component requires from and provides to its neighbors.
A sixth principle, reliability engineering, underlies the operational pillars (Observability, Scalability) and provides the framing for graceful degradation: when a component fails, the system should fail safely rather than catastrophically, and the failure should be visible. Agentic systems that “succeed silently with degraded quality” — for instance, falling back to a less-capable model without alerting on the quality drop — accumulate latent problems that surface as incidents later.
The ORCHIDEAS pillars are organized so that each one applies one or more of these disciplines to a specific design surface. Autonomy applies fail-safe defaults and separation of privilege to action boundaries. Identity & Intent applies capability-based security and complete mediation to authorization. Data & Memory Governance applies least privilege and compositionality to data lifecycle. Context applies zero trust to the runtime window. Runtime applies complete mediation and defense in depth to in-flight decisions. Human Oversight & Override applies psychological acceptability and separation of privilege to the human-AI interface. Observability applies open design and reliability engineering to the surveillance layer. Eval applies compositionality (in CI/CD form) to validation. Scalability applies economy of mechanism and reliability engineering to operational design.
Figure 2. Engineering disciplines that ground ORCHIDEAS and keep the pillars tied to established security and reliability practices.
The Nine Pillars in Design Sequence
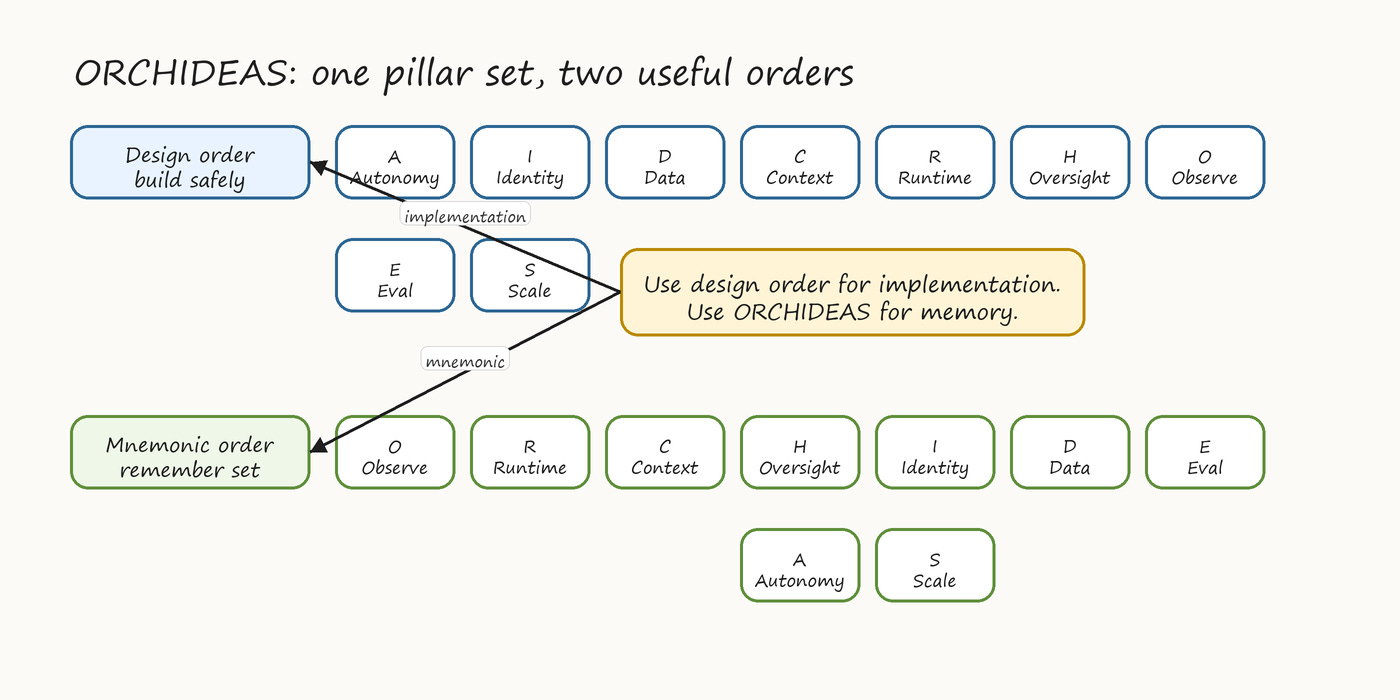
The pillars are presented below in the order they should be addressed when designing a new agentic AI system. The acronym ORCHIDEAS is a mnemonic; the design order is the implementation order. Skipping pillars early produces systems where later pillars cannot be cleanly applied — for instance, an agent built without explicit autonomy boundaries cannot have IBAC retrofitted later without rewriting the orchestration layer.
The mapping between ORCHIDEAS and the design sequence is given here for reference. ORCHIDEAS is the mnemonic order; the design sequence is the implementation order. The mnemonic order is O, R, C, H, I, D, E, A, S. The design sequence is A, I, D, C, R, H, O, E, S. Both refer to the same nine pillars; the difference prevents the acronym from implying a build order that would be unsafe.
Figure 3. Design-order versus mnemonic-order view of the same nine ORCHIDEAS pillars.
A — Autonomy
The first design decision
The autonomy question is the first architectural decision because every subsequent pillar depends on the answer. A platform building toward Level 1 agents (narrow assistive autonomy) has very different identity, context, runtime, and data requirements than one building toward Level 3+ agents (autonomous within domain). Deciding autonomy levels late forces all earlier pillars to be redesigned. Deciding them first allows each subsequent pillar to be sized appropriately.
The autonomy question is not binary but multi-dimensional. Each capability the agent has — read this resource, write that resource, call this external API, spend that much money, communicate with this counterparty, modify its own configuration — has its own autonomy setting that ranges from fully autonomous through autonomous-with-logging, autonomous-with-notification, autonomous-within-budget, requires-synchronous-approval, requires-asynchronous-review, all the way to never-permitted.
Several axes structure the decisions. Reversibility is the most important: actions that can be undone tolerate substantially more autonomy than actions that cannot. Blast radius matters: actions affecting one user warrant less scrutiny than actions affecting an entire tenant or all users. Cost matters: actions with significant monetary impact need explicit ceilings. External visibility matters: actions visible to customers, partners, or the public need confirmation paths that internal actions may not require. Compliance sensitivity matters: regulated actions (financial transactions, healthcare decisions, employment decisions) typically require explicit human gates regardless of the agent’s track record. And trust history matters: trust-progressive autonomy allows agents to earn broader scope through demonstrated reliable behavior, with rollback when behavior degrades.
A useful framework for stratifying autonomy is a five-plus-one level model, analogous to the SAE levels for autonomous vehicles but scoped to agentic action. Level 0 agents recommend and a human always acts. Level 1 agents perform narrow, low-risk tasks with human review of outcomes. Level 2 agents act autonomously within a defined scope and escalate at scope boundaries. Level 3 agents operate autonomously within a domain and surface exceptions. Level 4 agents operate autonomously across a bounded environment while humans supervise the fleet rather than individual actions. Level 5, full autonomy across all dimensions, remains aspirational and is not deployment-ready for consequential domains. Most production deployments should target Level 1 or Level 2 for consequential actions and reserve Level 3+ for narrow domains with strong reversibility, containment, and observability.
Engineering principles embodied
Autonomy is the pillar that operationalizes fail-safe defaults and separation of privilege. The default at every boundary is “this is not permitted unless explicitly authorized”; expanding autonomy requires deliberate sign-off rather than emerging from negative space. Separation of privilege manifests as multi-party approval for catastrophic-risk actions — two humans, or two independent agents plus a human — ensuring no single principal (human or AI) can authorize the most consequential operations alone.
The structural property to design for: an agent that wants to perform an action outside its autonomy bounds should find no path to do so within the architecture. The boundary is not a runtime check that could be bypassed; it is the shape of the interface itself.
MAESTRO threats relevant to Autonomy
Autonomy maps primarily to MAESTRO L3 (Agent Frameworks) where orchestration enforces boundaries, L7 (Agent Ecosystem) where multi-agent autonomy interactions occur, and L6 (Security & Compliance, vertical) where autonomy policy is governed.
Autonomy creep (L3, L6): gradual expansion without re-attestation. A team grants narrow autonomy at launch, encounters friction from approval gates, loosens boundaries to improve UX, and over months ends up with an agent operating well beyond what was originally authorized. The threat is organizational as much as technical; the mitigation is periodic re-attestation of autonomy levels with explicit sign-off and automated tracking of boundary changes.
Autonomy ambiguity (L3): unclear boundaries lead to either over-restriction (agent refuses legitimate actions) or under-restriction (agent takes unauthorized actions). The mitigation is explicit, machine-readable autonomy policy with clear precedence rules.
Approval fatigue (L6, L7): too many approval requests train human reviewers to rubber-stamp. The mitigation is risk-based approval routing that batches low-risk reviews and surfaces high-risk decisions with clear context.
Autonomy shopping (L3, L7): agents or users find paths achieving a goal without crossing approval gates — an agent forbidden from sending external email invokes a tool that triggers a webhook that sends external email. The mitigation is autonomy policy expressed at the effect level (outcomes), not just the action level (specific API calls), and cross-tool composition analysis.
Cascading autonomy failures (cross-layer): broad autonomy in one domain inherits effective autonomy in adjacent domains through tool composition. The mitigation is per-tool autonomy scoping, not per-agent.
Design patterns
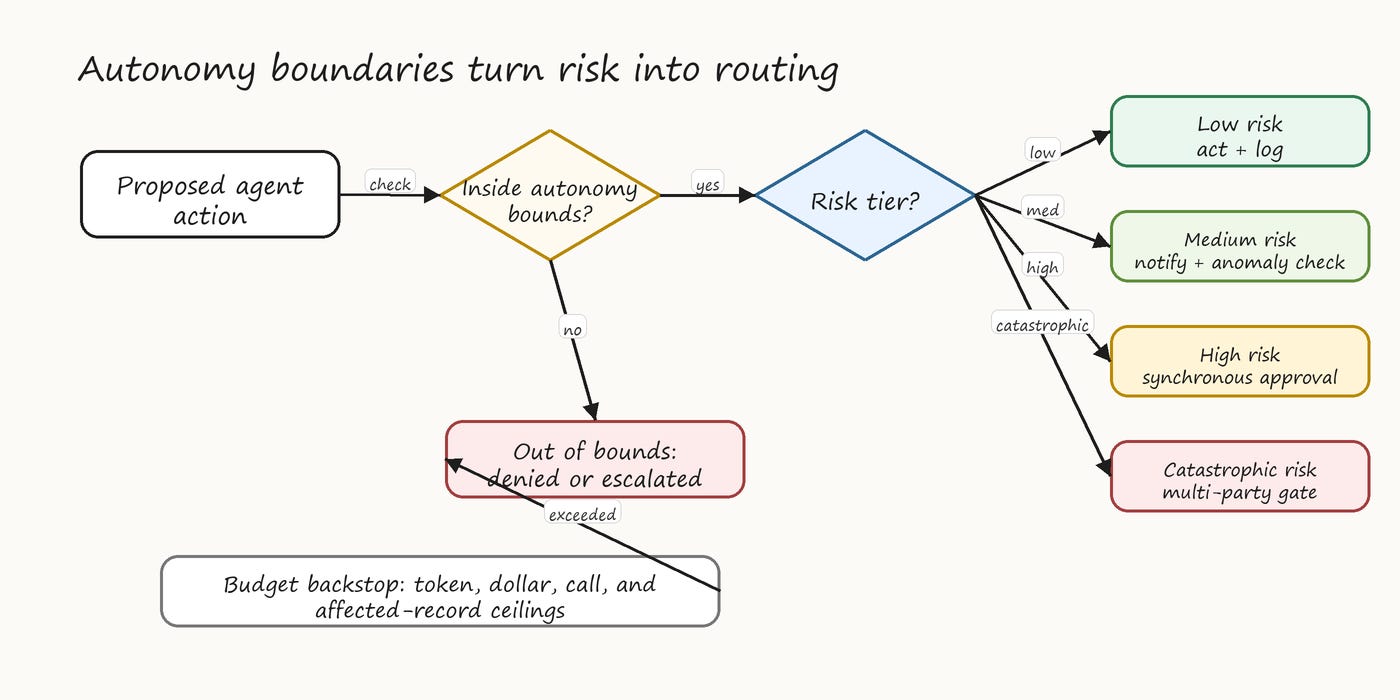
The reference pattern for high-stakes deployments uses tiered authorization. Low-risk actions flow through a fast path with logging only. Medium-risk actions flow through an enriched-context path with anomaly checks. High-risk actions require synchronous approval. Catastrophic-risk actions require multi-party approval. Budget-based autonomy provides a backstop: regardless of risk level, an agent that exceeds a configured budget of tokens, dollars, calls, or affected records halts and requires human review.
The structural guarantee: every action the agent takes flows through the autonomy decision point. There is no path that bypasses it. The decision point reads from machine-readable policy (OPA/Rego, Cedar) that is itself versioned, signed, and reviewed.
Figure 4. Autonomy boundary routing from proposed action to logging, notification, approval, multi-party approval, or denial.
I — Identity & Intent
Once autonomy boundaries are defined, the next question is who is doing the acting and on whose behalf. Identity establishes the principal; intent establishes the purpose. Both are required before any data access, tool call, or action can be authorized. Building data governance, context handling, or runtime enforcement before identity is solved produces systems whose authorization model is implicit and inconsistent across components — exactly the seam where attacks succeed.
The uncanny valley of agentic identity
Traditional identity systems split into two regimes. Human identity is built around interactive authentication, contextual signals, and slow-changing entitlements expressed through roles and group memberships. Workload identity — service accounts, API keys, mTLS certificates, SPIFFE IDs, OIDC tokens — is built around cryptographic attestation, short-lived credentials, and call graphs that can be statically reasoned about.
Agentic systems fall into the uncanny valley between these regimes. An agent is a workload by execution model: it runs in a container, holds credentials, makes API calls. But it is human-like in decision-making: it interprets ambiguous instructions, exercises judgment, composes novel sequences of actions, and acts on behalf of a human whose authority it inherits in some delegated form. Applying human identity controls (MFA, behavioral analytics tuned for humans) misfits the workload nature; applying pure workload identity controls (static service accounts with broad scopes) ignores that agents make value-laden decisions and can be steered by adversaries. Organizations that fail to recognize this valley grant agents service-account-style blanket permissions, then discover that prompt injection turns those permissions into an attacker capability.
The maturation path layers three components. The base layer is cryptographic workload identity (SPIFFE/SPIRE, cloud-native workload identity federation, TPM-rooted attested certificates) that proves what code is running. The middle layer is delegated authority (OAuth 2.0 token exchange RFC 8693, capability tokens, step-up authentication callbacks) that proves on whose behalf the agent acts. The top layer, still maturing, is intent attestation: a verifiable claim about what the agent is currently trying to do, bound to the specific task and revocable when the task completes.
Intent-Based Access Control
Conventional access control answers the question “is this principal allowed to perform this action on this resource?” For agents, that question is insufficient. An agent with legitimate access to a customer database may have a legitimate need to read one customer’s record and no legitimate need to exfiltrate the entire table; both operations may satisfy traditional RBAC or ABAC policies. Intent-Based Access Control (IBAC) adds a third dimension: the action must be consistent with the agent’s currently authorized intent.
When a user initiates a task, the orchestrator mints an intent token capturing the natural-language goal, a structured representation extracted by a classification model, the scope of resources the goal could legitimately touch, expected action types, a budget (in API calls, tokens, or time), and a TTL. Downstream policy decision points evaluate not just identity and resource but the active intent token, rejecting actions that fall outside the declared scope.
Intent misalignment becomes a first-class security threat with three primary vectors. External manipulation occurs when a user crafts a request that maps to a benign intent but is designed to be elaborated into a harmful action sequence. Adversarial prompt injection occurs when untrusted content mutates the agent’s working intent mid-task. Model hallucination occurs when the model, given a vague task, invents a plausible but unauthorized sub-goal. IBAC defends against all three by requiring every consequential action to trace back to the attested intent.
Engineering principles embodied
Identity & Intent applies capability-based security and complete mediation. Authority is conveyed through unforgeable, narrowly scoped capability tokens — never through ambient permissions tied to a session or role. Every action passes through a mediation point that checks the capability against the policy; there are no privileged code paths that skip the check.
The structural property: an agent in possession of authority for one task cannot use that authority for a different task, because the capability binds to the intent ID and the authorization check verifies the binding by construction.
MAESTRO threats relevant to Identity & Intent
Maps primarily to L6 (Security & Compliance), L3 (Agent Frameworks), with secondary impact on L4 (Deployment) and L7 (Ecosystem).
Agent impersonation (L7, L6): mutual authentication, capability tokens that cannot be replayed, workload attestation binding credentials to verified code.
Credential theft and replay (L4, L6): short TTLs (minutes, not hours), narrow scopes, binding credentials to workload attestation so they cannot be used outside the verified execution environment.
Confused deputy across handoffs (L3, L7): attenuated delegation — Agent B receives a capability token strictly narrower than Agent A’s, scoped to the specific subtask.
Intent drift through prompt injection (L1, L3): re-deriving authorization from the originally attested intent rather than from the agent’s current reasoning.
Hallucinated intent (L1): vague tasks should fail attestation rather than be elaborated into plausible-sounding goals.
Privilege escalation through tool composition (L3, L7): composition-aware policy that reasons about effect chains, not just individual tool permissions.
Design patterns and anti-patterns
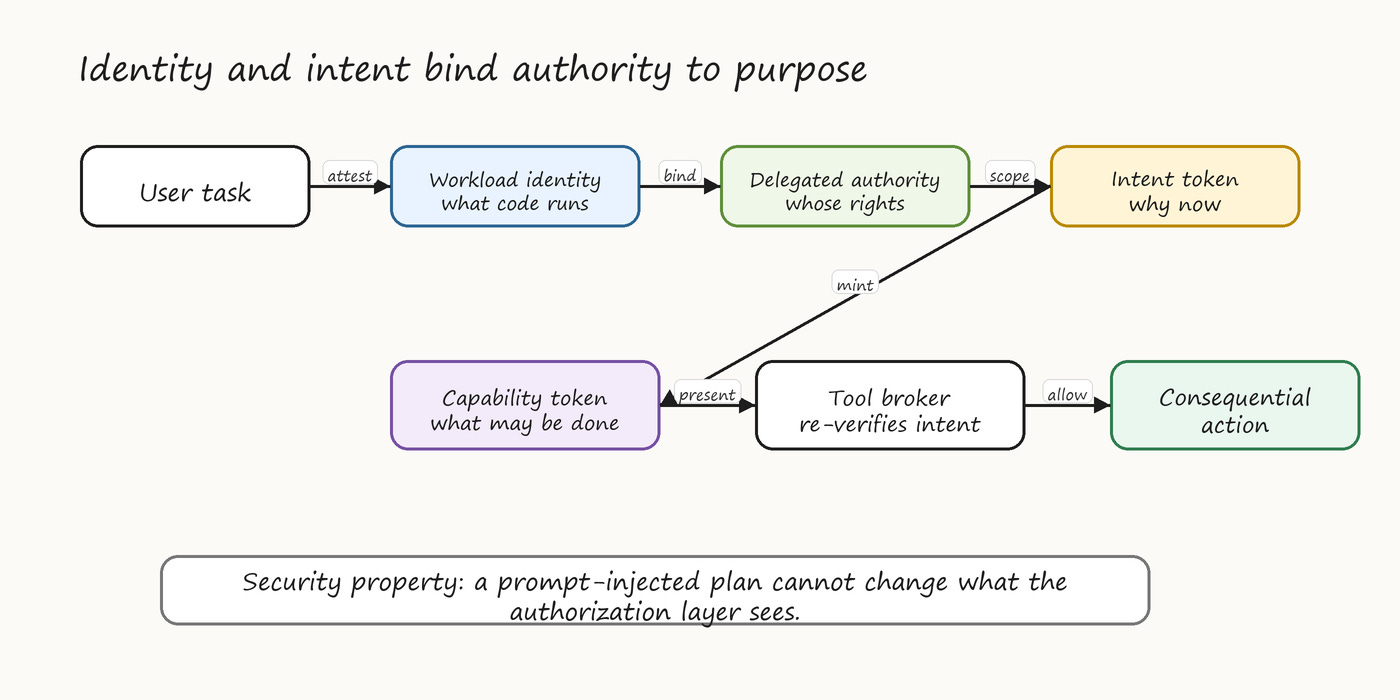
The reference architecture binds four elements at every consequential action: workload identity, delegated user identity, active intent token, and a per-action capability token derived from the three. The capability token is what passes to downstream services. It is short-lived, narrowly scoped, and embeds the intent ID.
Two anti-patterns recur. The omnipotent agent service account — a single broadly scoped account used by all agent instances — collapses the identity dimensions, makes auditing meaningless, and converts every prompt injection into worst-case escalation. Passing user credentials through to the agent — forwarding the user’s bearer token so the agent can act “as the user” — breaks delegation hygiene and creates significant credential exposure. Token exchange to a narrower delegated credential is always preferable.
Figure 5. Identity and intent chain that binds workload identity, delegated authority, intent, capability, and broker mediation.
D — Data & Memory Governance
Identity authorizes principals; data governance defines what the principals are authorized over. Before designing context, runtime, or observability, the platform team must answer: what data exists, where does it live, how is it classified, who can access it, how does classification propagate, and how long is it retained. Building agent context handling before the data classification is settled produces systems where sensitive data leaks into unprivileged context paths and where deletion requests have no clean propagation path.
The data lifecycle of an agent
Agentic systems depend on a wide data lifecycle. The training and fine-tuning data behind any custom models. The RAG corpora the agent retrieves from. The agent memory it persists across sessions. The data it generates as derivative artifacts (summaries, embeddings, extracted facts). The classification labels that should propagate from source systems through every downstream operation. None of this lives in the runtime context window, and none of it is owned by other pillars.
Data & Memory Governance owns: training data lineage (consent, license, bias evaluation); RAG corpus governance (source vetting, freshness, poisoning monitoring, access alignment); agent memory persistence (vector databases, episodic memory, fact stores, preference profiles); PII handling (detection, redaction, tokenization, audit, retention); data residency and sovereignty (where data can reside and be processed); data classification propagation (labels flow through retrieval, context, output, logs); and retention and right-to-erasure (deletion semantics that propagate through derived stores).
Engineering principles embodied
Data & Memory Governance applies least privilege and compositionality to the data lifecycle. Least privilege at the data layer means: the agent retrieves only the data needed for the task, classification flows with the data, and downstream operations inherit restrictions. Compositionality means that the security properties of derived data (embeddings, summaries) are derivable from the source — there is no place where classification can be “lost” because the data went through an operation that did not understand it.
The structural property: any data the agent touches carries its classification with it through every subsequent operation. There is no path where a “restricted” document gets summarized into an “unclassified” output by accident, because the classification is propagated by construction.
MAESTRO threats relevant to Data & Memory Governance
Maps primarily to L2 (Data Operations), with L1 (Foundation Models) for training data and L6 (Security & Compliance) for governance.
Data poisoning of training and fine-tuning data (L2 → L1): the canonical cross-layer cascade. Poisoned data ingested during a retraining cycle embeds corruption into model weights, manifesting as compromised behavior at L7. Mitigations: signed datasets with provenance, automated anomaly checks on incoming data, isolation between training data sources and production retrieval corpora, red-team testing for backdoor triggers post-training.
RAG corpus poisoning (L2, L3): an insider or compromised contributor adds malicious content. When retrieved into context, the content contains prompt injection payloads. This is one of the most underestimated production threats because it weaponizes the very content the system was designed to use. Mitigations: source vetting, content classification on ingestion, change tracking with audit, periodic adversarial retrieval testing, isolation between user-contributed and curated content.
Embedding inversion attacks (L2): given access to a vector database, an attacker reconstructs the original text from embeddings — sometimes substantially. Mitigations: treat vector databases as containing the original text for access control purposes; encrypt embeddings at rest where warranted; consider differentially-private embedding techniques for highly sensitive data.
Memory contamination across sessions or tenants (L2): one user’s data leaks into another user’s context through memory persistence. Mitigations: strict per-tenant memory scoping; separate physical or logical vector indexes for confidential data; explicit access control on memory retrieval.
PII leakage through derived data (L2, L5): embeddings, summaries, and logs derived from PII may not themselves be classified as PII in source systems, but reconstruction or correlation attacks can extract personal information. Mitigation: classification inheritance — any data derived from classified inputs inherits at least the classification of its inputs.
Right-to-erasure failures (L2, L6): when a user requests deletion, agents may have copies in memory stores, embeddings, summaries, fine-tuning data, and logs. Mitigations: per-user data inventory across all stores; deletion workflows that propagate to derived data; documentation of any data that cannot be deleted with explicit user notice; architectural choices that minimize the proliferation of personal data copies.
Data residency violations (L4, L6): an agent retrieves EU-resident data and processes it through a model API in a non-compliant region. Mitigations: residency labels on all data; routing logic that respects residency at the inference layer.
Design patterns
The reference architecture centers on a data classification service that every data-producing and data-consuming component consults. Source data is classified at ingestion; derived data inherits classifications from inputs; access control at retrieval, context assembly, and output enforces classifications. Memory stores are partitioned by tenant and by classification level. RAG pipelines treat retrieved content as untrusted by default. Embedding stores are governed at the same level as the raw text they were derived from.
A separate but related pattern is the data inventory: a continuously updated map of what personal and sensitive data exists where, how it flows through the agent system, who has access, and how long it persists. This is the artifact compliance teams need to demonstrate control and the operational tool incident response teams need when investigating a breach.
A common anti-pattern is treating the vector database as “just” a search index with relaxed access controls because “it’s only embeddings.” Embedding inversion plus the accumulation of context summaries means vector stores end up containing reconstruction-grade representations of sensitive data. Treat them as primary data stores for governance purposes.
C — Context
With autonomy, identity, and data governance in place, the next question is what the agent perceives at decision time. Context is where data, instructions, and untrusted content meet inside the model’s working window. Designing context before identity and data is unsolved produces structurally compromised agents — the context handling has no way to know what trust level to assign each segment because the classifications were never established.
Context as a security dimension
The context window is not a working buffer; it is the entire universe the agent perceives at the moment of decision. Anything in that window shapes behavior, and anything that shapes behavior is in scope for security analysis. Treating context as a purely architectural concern misses that context window integrity has direct security consequences comparable to a misconfigured firewall.
Applying the CIA triad to the context window itself yields a useful framing. Confidentiality asks what is in the context, who can see it, and what happens if it is logged or leaked. Integrity asks whether the context can be modified by untrusted sources between read and act — indirect prompt injection is a pure integrity attack. Availability asks whether an adversary can exhaust, truncate, or fill the context with noise to push legitimate instructions out.
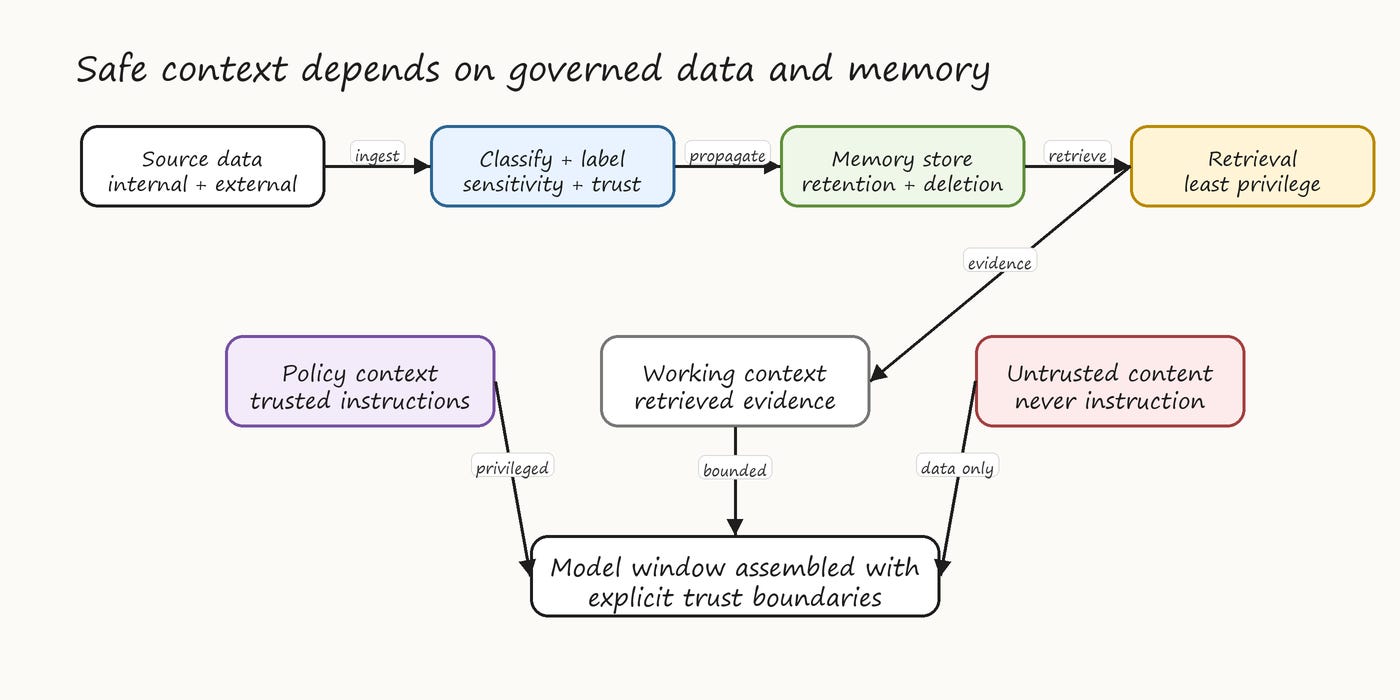
A typical agent context contains layered content with very different trust properties. At the top, a system prompt and policy block, authored by the platform team and effectively immutable from the agent’s perspective. Below that, user-provided input, untrusted by default. Below that, retrieved content from RAG pipelines, often the lowest-trust segment because it can be authored by anyone whose documents end up in the corpus. Interleaved throughout, tool call results, carrying the trust of the tool. Finally, agent-generated content — prior reasoning, scratchpad notes — which inherits the integrity properties of everything that came before.
Engineering principles embodied
Context applies zero trust to the runtime window. The architecture conditions the model on segment provenance: instructions in low-trust segments are data, not directives. The structural property: there is no path by which content from an untrusted source becomes interpreted as instruction without crossing an explicit trust-elevation boundary that requires authorization.
The error most systems make is treating context as a flat token stream. A more defensible architecture tags each context segment with provenance and trust level, and the model is conditioned to respect the tags. No language model perfectly honors such conditioning, but the combination of trust tagging, structural separation, and downstream policy enforcement raises the bar significantly.
MAESTRO threats relevant to Context
Maps primarily to L3 (Agent Frameworks) and L1 (Foundation Models), with L2 (Data Operations) secondary.
Indirect prompt injection (L3, L1): the canonical attack. A user asks the agent to summarize a webpage; the page contains text designed to manipulate the agent. Layered mitigations: input transformations on untrusted content; prompt-layer trust tagging; runtime-layer tool call validation against current intent; action-layer confirmation for sensitive operations.
Context corruption through compaction (L3): summarization drops policy instructions; the agent loses constraints. The fix is hierarchical context — a sealed top layer (system prompts, policies) never compacted, a sticky middle layer of session-critical facts that resists summarization, and a rolling tail that can be compacted. Many systems re-inject the policy block before every model call rather than relying on it remaining in context.
Cross-tenant context leakage (L3, L4): shared caches, embedding stores, or KV cache reuse mix context between tenants. Mitigations: tenant-scoped cache keys, separate vector indexes for confidential corpora, explicit context isolation in the inference layer.
Context exhaustion attacks (L3, L1): adversarial inputs consume context budget and push policy out. Mitigation: sealed policy regions that consume from a separate budget.
Context-as-exfiltration-channel (L3, L6): agents include context content in tool calls or external responses, leaking what should remain internal. Output filtering and content classification on outgoing data are necessary.
Design patterns
A robust context security architecture maintains a provenance graph for every context element, so any token can be traced to its source. It enforces segregation through structural delimiters and role-based channels. It performs input transformations on untrusted content. It preserves security invariants across summarization. It logs context snapshots at decision points for post-incident forensics.
Figure 6. Data, memory, and context governance showing how classification, retention, retrieval, and trust segmentation shape the model window.
R — Runtime
With autonomy, identity, data, and context in place, the system has the substrate to make decisions. Runtime is what watches those decisions as they happen and intervenes when they go wrong. Building runtime enforcement before the prior pillars are settled produces enforcement that has nothing meaningful to check against — runtime rules need attested intents to verify alignment, classified data to enforce restrictions, and trust-tagged context to evaluate.
Runtime as last line of defense
Pre-deployment evaluation is necessary but insufficient. No eval suite covers every adversarial input, every tool composition, every emergent interaction. Runtime controls are the last line of defense — for many threats, the only meaningful one. A prompt injection variant invented yesterday will not be in your eval set; runtime detection and enforcement is what catches it.
Runtime comprises three capabilities. Verification checks each step against policy and intent. Enforcement takes action when verification fails — block, redact, transform, escalate. Dynamic intervention updates behavior in flight without redeploying, isolates misbehaving agents, rolls back actions.
Architecture for runtime control
The reference architecture places an LLM gateway (sometimes called AI proxy or AI firewall) in front of every model invocation. Direct model API access from application code is disallowed; all calls flow through the gateway, which enforces authentication, applies content policies on input and output, performs PII detection and redaction, rate-limits, attaches cost accounting, and emits telemetry. This is the chokepoint that makes uniform policy enforcement possible across a heterogeneous fleet.
A complementary chokepoint sits at the tool invocation layer. Tools are called through a tool broker that validates each call against the agent’s identity, the active intent token, and policy. The broker is where IBAC is enforced.
Sandboxing matters for any tool that executes generated code or processes untrusted data. Code execution belongs in a properly isolated sandbox: containers with strict resource limits, no outbound network access except through the broker, ephemeral filesystems, no access to the agent’s credentials.
Engineering principles embodied
Runtime applies complete mediation and defense in depth. Complete mediation: every action passes through a verification point; there are no privileged paths. Defense in depth: multiple verification layers (schema validation, intent alignment, policy check, content filter, anomaly detection) operate independently, so the attacker must defeat all of them while the defender needs only one to catch the attack.
The structural property: an action that does not pass through the gateway and broker cannot reach its target. There is no out-of-band path to the model or to the tools.
MAESTRO threats relevant to Runtime
Maps primarily to L3 (Agent Frameworks) and L4 (Deployment), with L6 (Security & Compliance) for policy enforcement.
Tool misuse and unsafe tool calls (L3, L7): tool-call validation gates — schema validation, allowlisted tools/actions, parameter constraints. Schema validation on every call is the cheapest and most effective check.
Container escape from sandboxed code execution (L4): gVisor or Firecracker-style isolation; no host filesystem access; kernel-level resource limits; no outbound network except through broker.
Pipeline compromise (L4): signed artifacts, reproducible builds, deployment gate reviews, scoped agent RBAC, container signing.
Goal misalignment cascades (L3 → L7): an agent under prompt injection performs a tool call that returns a result further corrupting reasoning. Mitigation: intent re-verification at each call, output filtering on tool responses.
Rate limit and resource exhaustion (L3, L4): per-task and per-agent budgets, circuit breakers, timeout enforcement.
Verification, enforcement, and dynamic intervention
Output schema validation is the cheapest and most effective runtime check. If a tool call is supposed to produce structured output, validate that it does — agents under prompt injection often produce malformed responses, and refusing to proceed on schema violation interrupts many attacks. Action confirmation for high-risk operations requires either explicit human approval or a second model invocation with adversarial framing to challenge the proposed action.
Intent re-verification is the IBAC counterpart at runtime. Before any consequential action, the system re-derives whether the action falls within the declared intent, operating from the originally attested intent rather than from the agent’s current reasoning (which may have been corrupted).
When verification fails, enforcement options include blocking, redacting, transforming, escalating, or quarantining. Dynamic intervention enables responses without redeployment — policy bundles hot-load, rate limits tighten in real time, specific tool capabilities are temporarily revoked across the fleet when a vulnerability is disclosed.
Action rollback is the most ambitious capability. Designing agent tools with reversibility in mind — soft-delete defaults, transactional staging, two-phase commit for high-stakes actions — preserves the option to undo when something goes wrong.
