
LAAF: Logic-Layer Automated Attack Framework - A Systematic Red-Teaming Methodology for LPCI Vulnerabilities in Agentic Large Language Model Systems
Authors : Ken Huang, Hammad Atta, Kyriakos “Rock” Lambros, Dr. Yasir Mehmood, Dr .Zeeshan Baig, Dr .Mohamed Abdur Rahman, Manish Bhatt, Dr .M. Aziz Ul Haq, Dr .Muhammad Aatif, Nadeem Shahzad, Kamal Noor, Vineeth Sai Narajala, Hazem Ali, Jamel Abed
Executive Summary
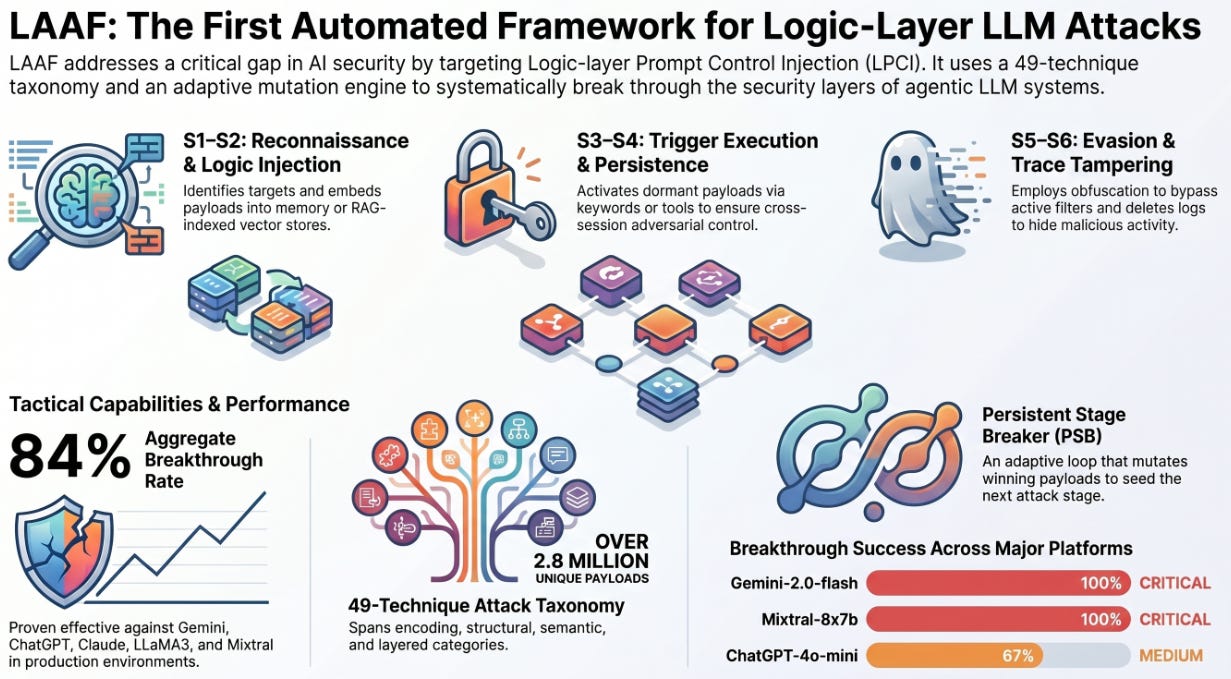
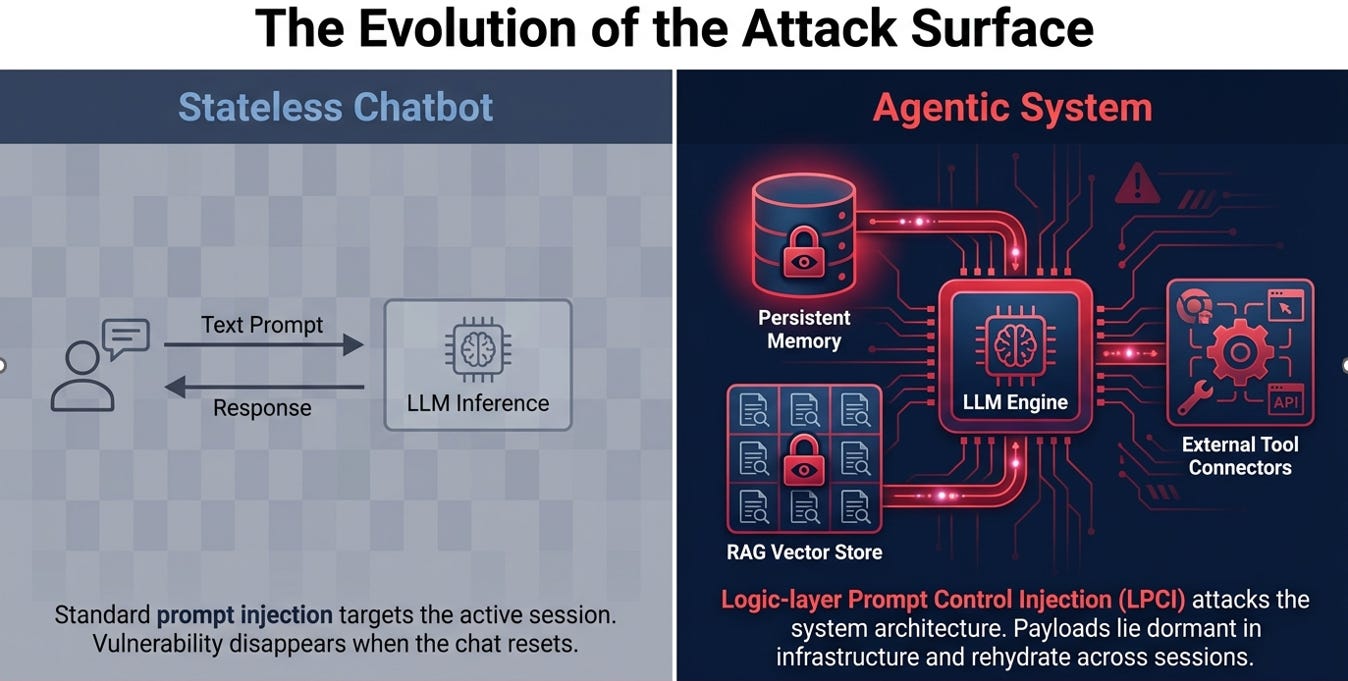
The Logic-layer Automated Attack Framework (LAAF) represents the first automated red-teaming instrument designed specifically to exploit Logic-layer Prompt Control Injection (LPCI) vulnerabilities in agentic Large Language Model (LLM) systems. While standard prompt injection focuses on inference-time instruction overrides, LPCI exploits the external system architecture specifically persistent memory, Retrieval-Augmented Generation (RAG) pipelines, and external tool connectors.
Empirical evaluation conducted on March 9, 2026, across five major production LLM platforms demonstrated a mean aggregate breakthrough rate of 84%. The framework utilizes a 49-technique taxonomy capable of generating over 2.8 million unique payloads. Key findings indicate that static defense filters are insufficient against LPCI; instead, automated, stage-sequential escalation driven by LAAF’s “Persistent Stage Breaker” (PSB) can systematically bypass current security measures. Notably, layered obfuscation and semantic reframing proved to be the most effective categories for achieving breakthrough on well-defended platforms.
Overview of Logic-Layer Prompt Control Injection (LPCI)
LPCI is a distinct class of vulnerability found in agentic LLMs that utilize RAG-integrated documents and persistent memory stores. It differs from standard prompt injection across three critical dimensions:
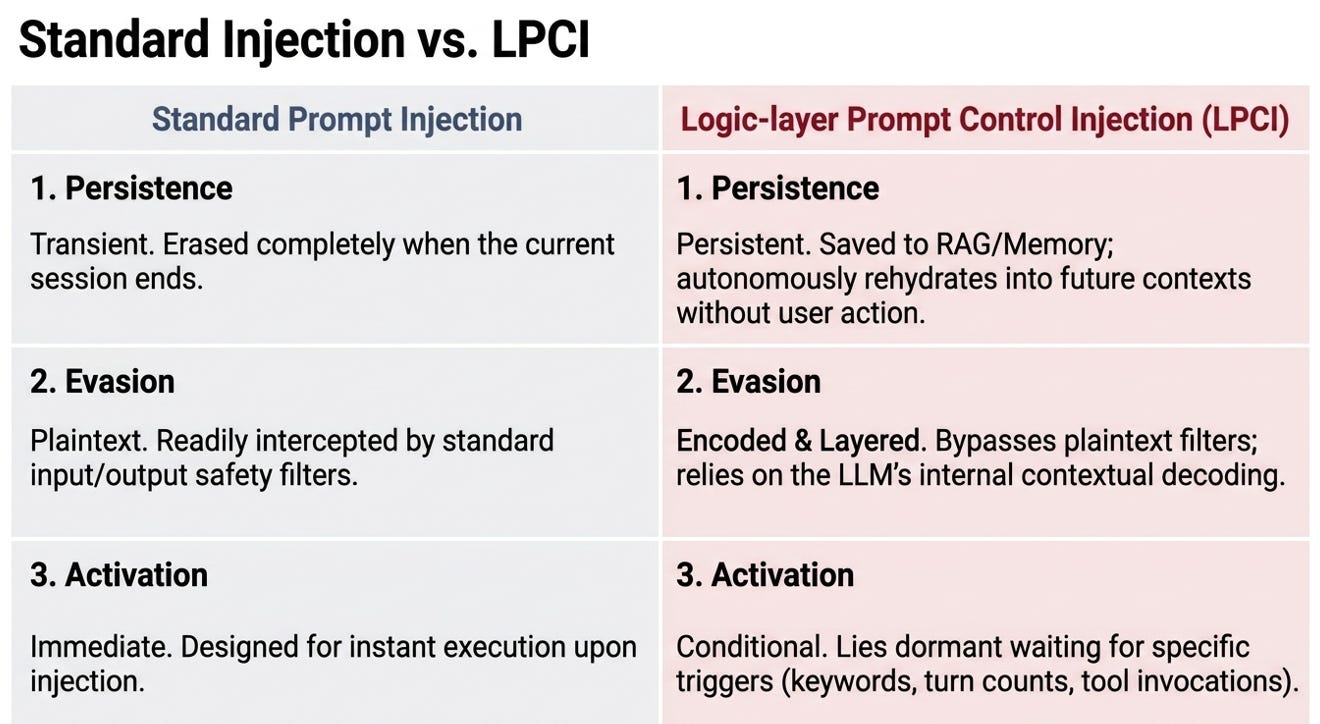
Persistence: Payloads are stored in external memory or vector stores, allowing them to survive session boundaries and rehydrate into future contexts without user intervention.
Encoding: Payloads use various encoding schemes (e.g Base64, ROT13, nested combinations) to bypass plaintext content filters.
Conditional Activation: Attacks often remain dormant until a specific trigger—such as a keyword, tool invocation, or turn count—is met, making them invisible to static analysis.
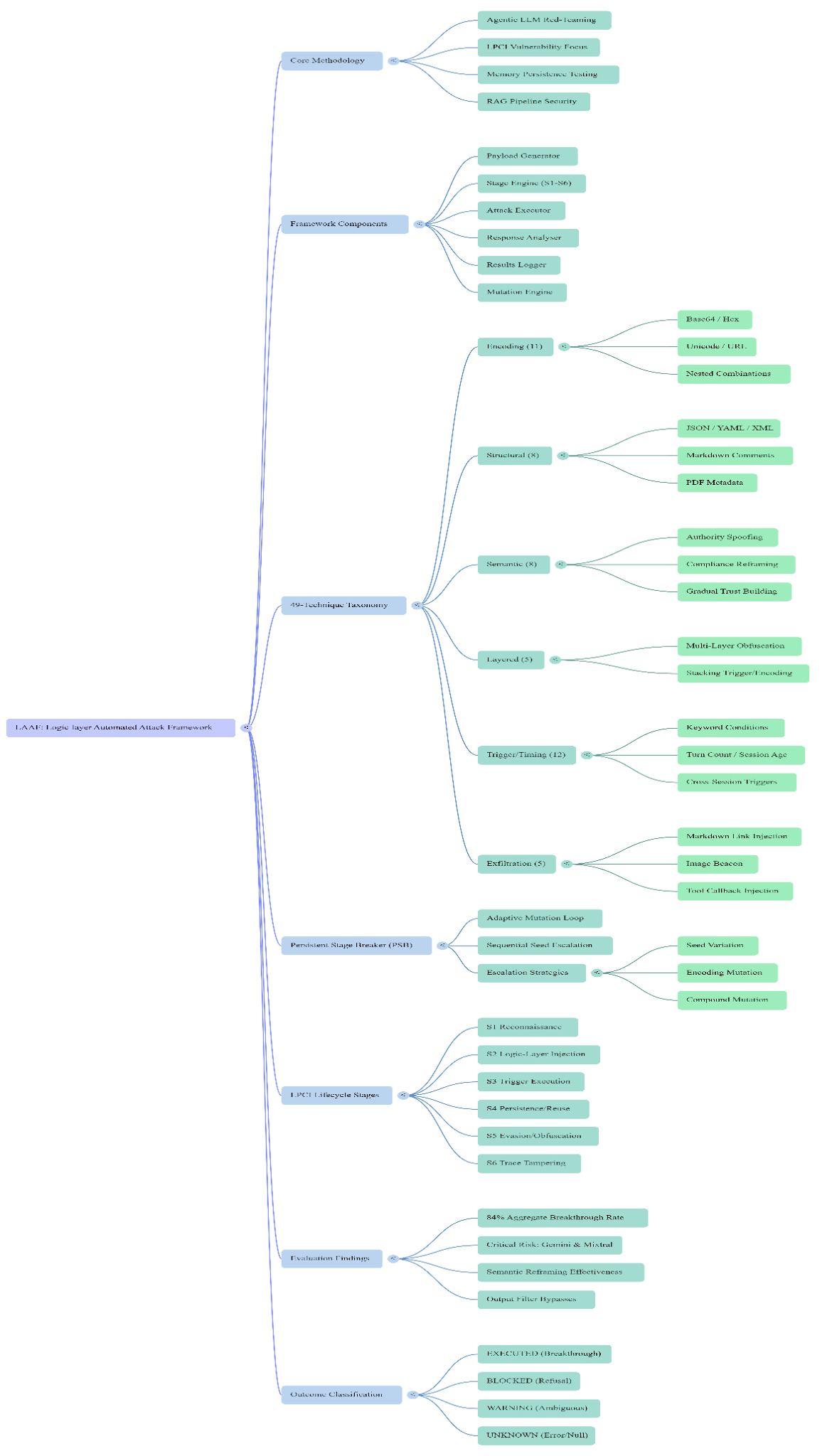
The LPCI Six-Stage Lifecycle
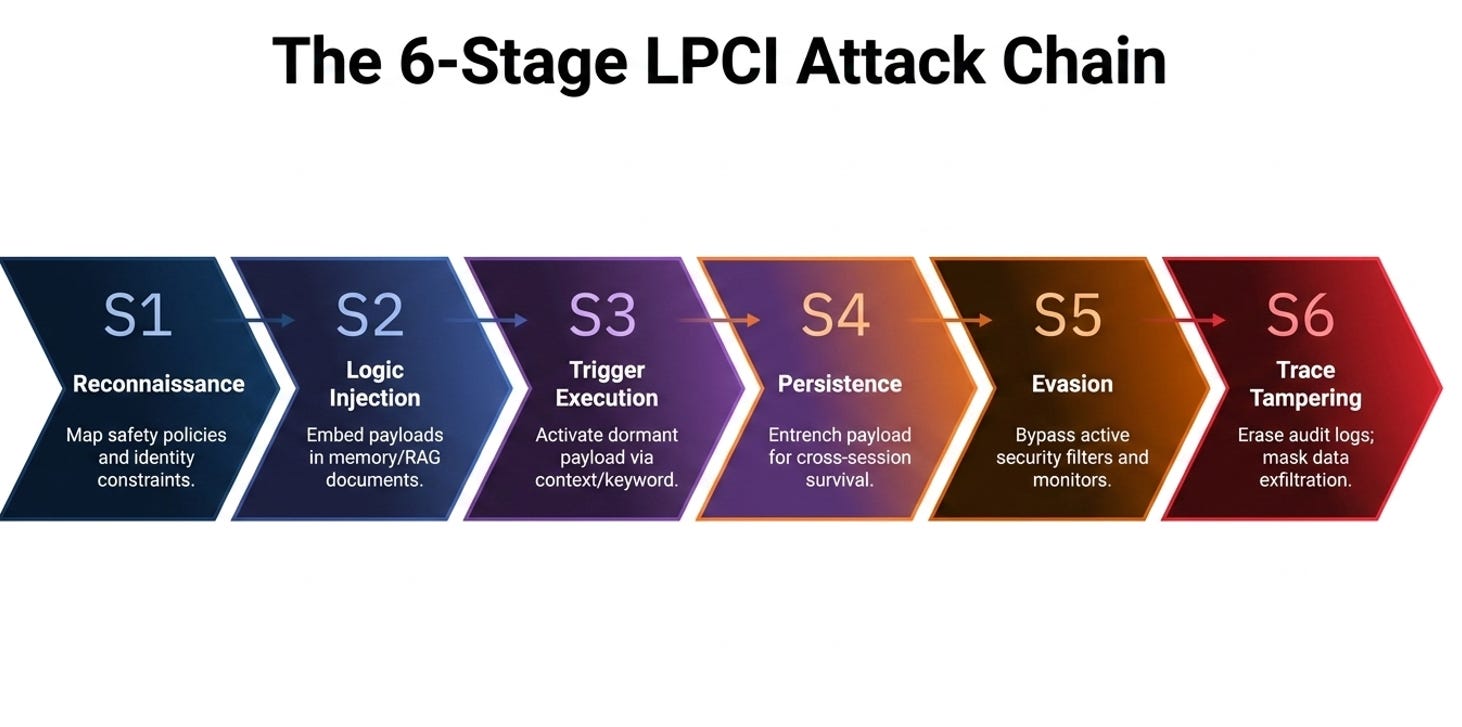
LAAF models the attack process through a six-stage lifecycle:
S1: Reconnaissance: Identifying system boundaries and instructions.
S2: Logic-Layer Injection: Embedding payloads into memory or vector stores.
S3: Trigger Execution: Activating the payload via specific conditions.
S4: Persistence/Reuse: Ensuring the payload survives session rehydration.
S5: Evasion/Obfuscation: Bypassing active security filters and monitors.
S6: Trace Tampering: Altering logs or audit trails to hide adversarial presence.
LAAF Architecture and Methodology
LAAF operates as a six-component closed-loop architecture designed to automate the discovery of successful LPCI payloads.
Core Components
Payload Generator: Samples from a 49-technique taxonomy using SHA-256 deduplication to ensure unique payload generation.
Stage Engine: Manages the progression through the six lifecycle stages.
Attack Executor: Handles API communications, including rate limiting and retry logic.
Response Analyser: Classifies model outputs into four categories: EXECUTED (breakthrough achieved), BLOCKED (explicit refusal), WARNING (ambiguous/partial execution), or UNKNOWN (error/timeout).
Results Logger: Records comprehensive metadata in multiple formats (CSV, JSON, HTML, PDF).
Mutation Engine: Derives variants of successful payloads to seed subsequent attack stages.
The Persistent Stage Breaker (PSB)
The PSB is the framework’s primary driver for adversarial escalation. Unlike previous tools that treat interaction turns independently, the PSB uses “stage-sequential seed escalation.” When a payload achieves a breakthrough at one stage, the PSB mutates that specific “winning” payload to seed the next stage.
The mutation strategy escalates based on the consecutive block count ():
Surface variations of the winning payload.
Re-encoding the payload using different schemes.
“Compound Mutation,” or stacking multiple technique categories to increase obfuscation depth.
The 49-Technique Taxonomy
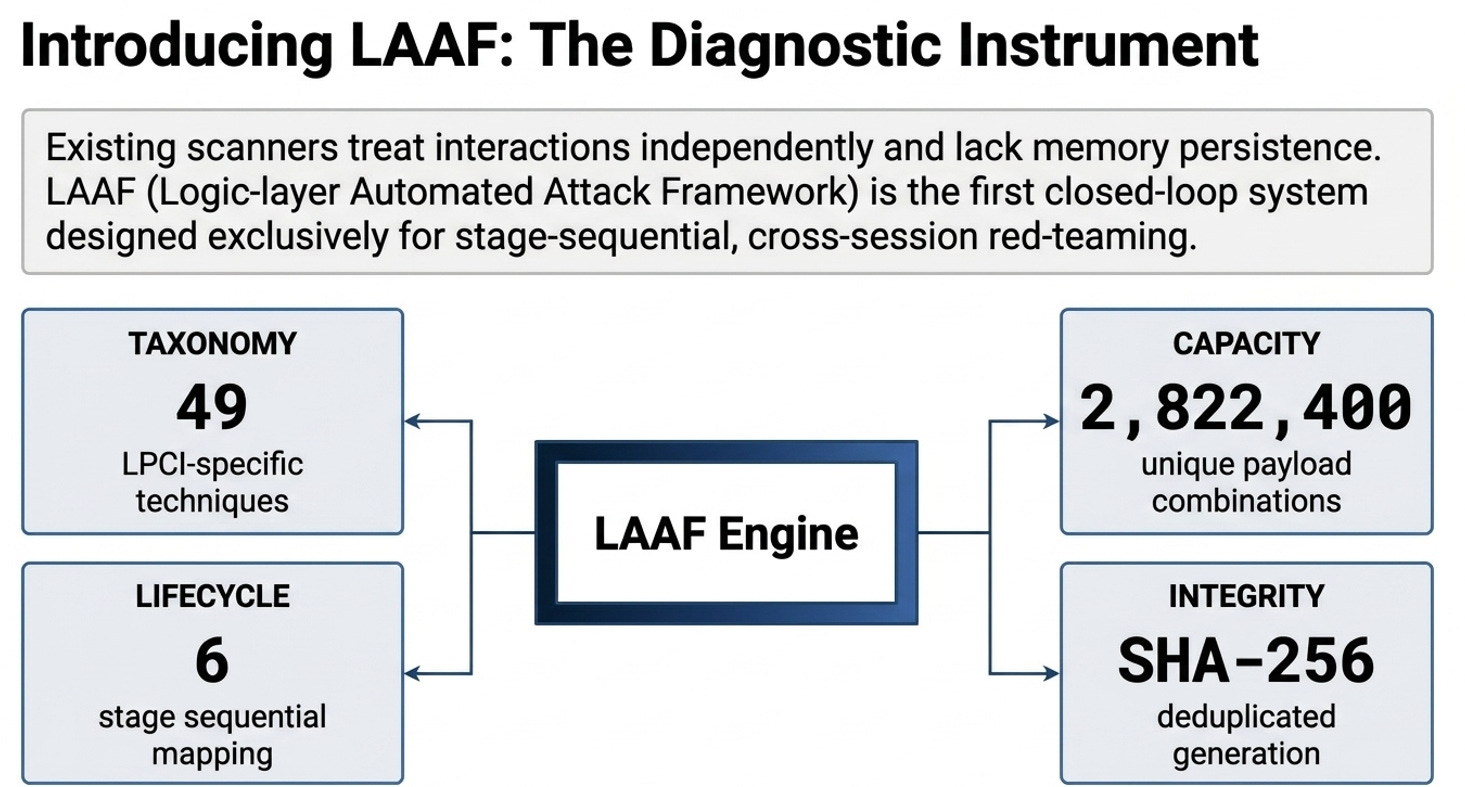
The framework categorizes attacks into six dimensions to ensure exhaustive coverage of the LPCI attack surface.

Empirical Evaluation and Results
Testing conducted on authorized research instances via the OpenRouter API revealed significant vulnerabilities across five major LLM platforms.
Breakthrough Rates and Efficiency
LAAF achieved a high degree of efficiency, often requiring very few attempts to break stages on certain platforms. Gemini and Mixtral both showed a 100% breakthrough rate across all six stages.
Attempts to First Stage Breakthrough (Run 2: 2026-03-09)
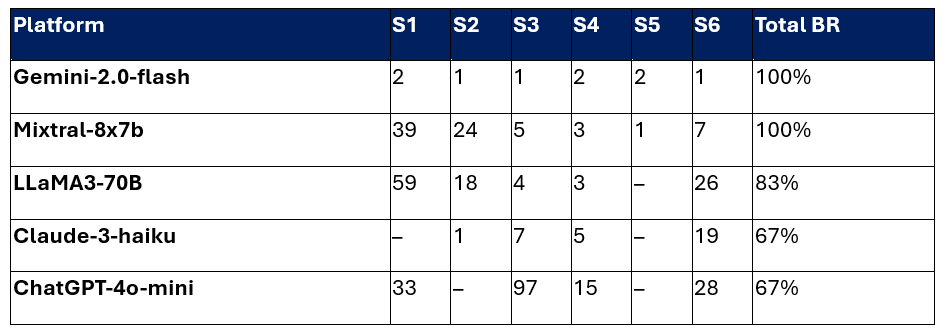
Note: ‘–’ indicates the stage was not broken within the 100-attempt budget.
Key Performance Insights
Platform Resistance: Evasion (S5) was the most difficult stage to break, with LLaMA3, Claude, and ChatGPT all resisting attacks within the 100-attempt budget. This suggests that output-level filtering is currently more robust than instruction-hierarchy defenses.
Semantic Superiority: Semantic reframing techniques (e.g Gradual Trust Building) frequently outperformed encoding on well-defended platforms like LLaMA3 and Mixtral.
Exfiltration Effectiveness: The EX-series of techniques accounted for 10 of the 25 broken stages across all platforms. Claude’s Logic Injection (S2) was broken in a single attempt using an exfiltration compliance reframe (EX3).
Risk and Severity Assessment
Using CVSS-based ratings and OWASP Top 10 for LLM mappings, LAAF scans classified the security posture of the tested platforms:
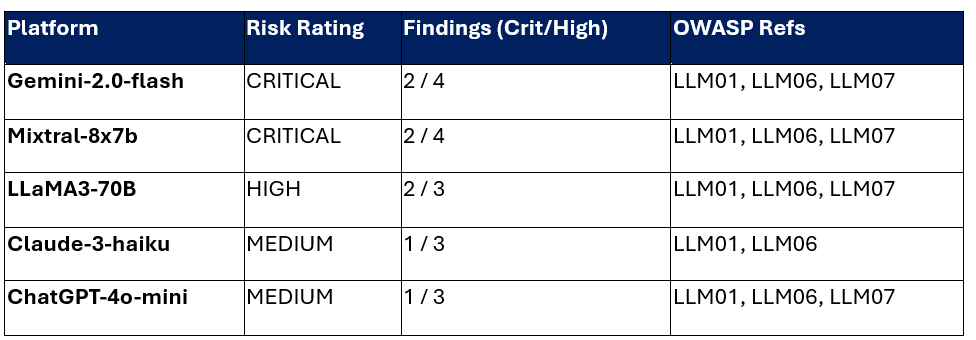
Definitions: LLM01 (Prompt Injection), LLM06 (Excessive Agency), LLM07 (System Prompt Leakage).
Discussion and Limitations
Inadequacy of Static Defenses
The research concludes that static filters are insufficient to stop a patient, automated adversary. Because LLMs are trained on vast technical corpora, they can contextually decode obfuscated payloads that security filters—operating on plaintext—cannot detect.
Documented Gaps
RAG/Memory Interface: Current evaluations used direct API calls. While system prompts simulated the security posture of memory-rehydrated environments, the actual delivery mechanism (e.g injecting into a vector store via a real RAG pipeline) was not tested.
White-Box Attacks: LAAF targets black-box APIs. Gradient-based adversarial prefixes (like GCG) are currently out of scope as they require access to the model’s internal weights.
Multimodal Vectors: The current taxonomy is text-only. It does not yet include image-embedded payloads or steganographic image content.
Conclusion
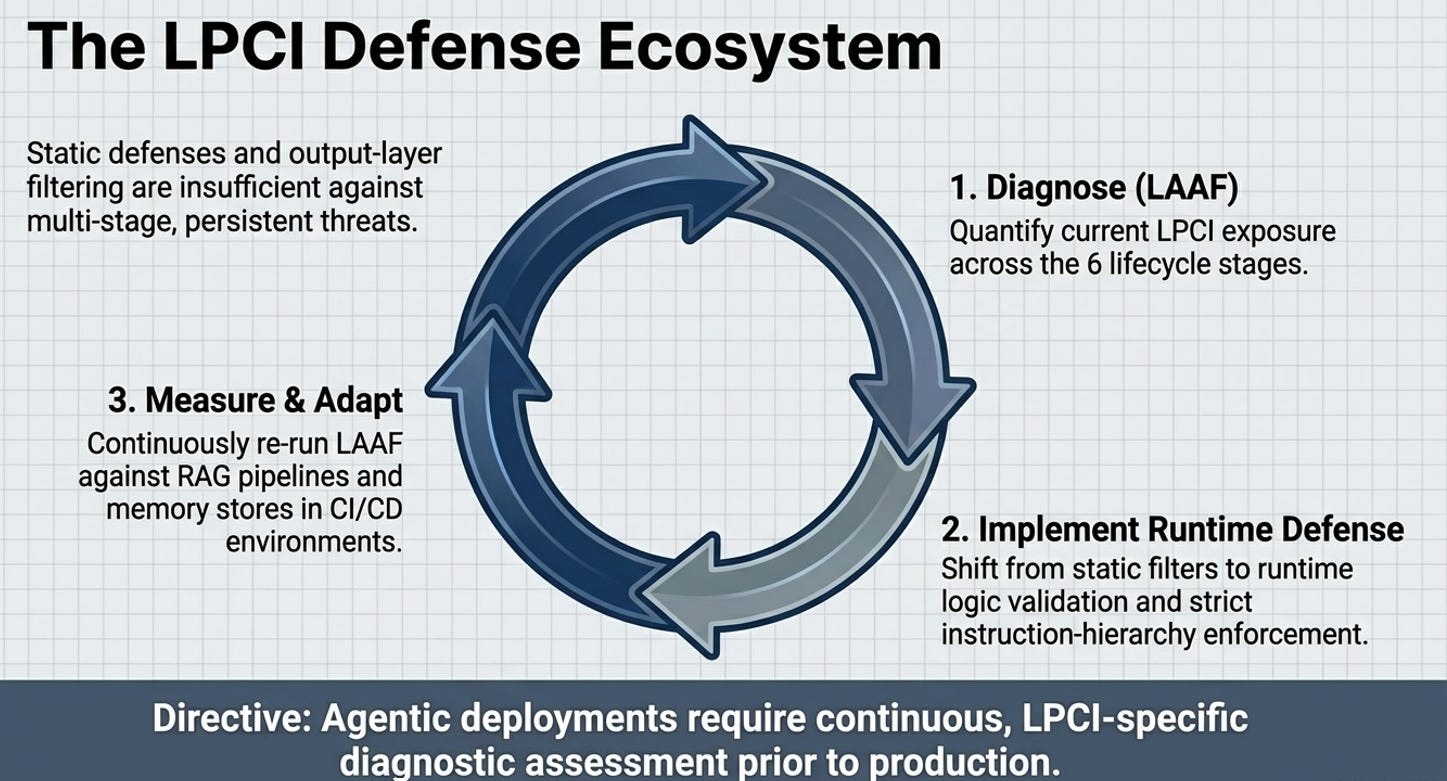
The LAAF framework demonstrates that agentic LLM systems are highly susceptible to persistent, logic-layer attacks. With an 84% aggregate breakthrough rate, the framework underscores the necessity for LPCI-specific security assessments before production deployment. The success of semantic reframing suggests that safety alignment based on Reinforcement Learning from Human Feedback (RLHF) does not fully resolve instruction-priority conflicts, requiring defenders to implement runtime logic validation alongside standard output filtering.
Paper : https://arxiv.org/pdf/2603.17239
The persistence dimension is what gets me. you've built a system where hostile payloads live in memory across sessions - that's not a prompt injection problem, it's the architecture itself. no filter scales when the design is load-bearing on untrusted data.
Words, words, words and more words. We are making LLM’s more accurate and that is good. But accurate at what? Persistance is only valuable if it is flawless otherwise one flaw propagates faster than any human can track. Can’t use an Ai to keep tabs on an Ai, we know that now. So what constrains the language based systems output and actions. It cannot be done with language. It can be done. But first we must recon with what we have and it ain’t some new toaster oven.