
Recursive Self-Improvement: A Technical Deep Dive into AI Systems That Help Build Their Successors (Claude Code vs. Hermes Agent)

Recursive self-improvement, or RSI, is not a magic phrase for an intelligence explosion. It is a concrete engineering claim about closing a feedback loop. A system helps design, implement, test, and deploy a successor system. The successor is then better at the same kind of work, so the next cycle can run faster, wider, or with less human intervention. The loop may be weak, partial, and heavily supervised. It may be bottlenecked by compute, safety evaluation, human judgment, or organizational process. But once the loop exists, the important question changes from "Can AI assist AI researchers?" to "Which parts of AI research and development still require humans, and how quickly are those parts shrinking?"
The PDF supplied for this piece is Anthropic's "When AI builds itself," a public Anthropic Institute essay on recursive self-improvement. I will credit the source directly: Anthropic defines recursive self-improvement as the possibility that an AI system becomes capable of autonomously designing and developing its own successor, while stressing that this has not yet happened and is not guaranteed to happen. The live source is Anthropic, "When AI builds itself," https://www.anthropic.com/institute/recursive-self-improvement.
What makes Anthropic's essay useful is that it does not treat RSI as a philosophical abstraction. It decomposes the AI-development workflow into engineering, experimentation, review, research judgment, and organizational bottlenecks. It then gives evidence that AI systems are already accelerating several of those pieces: coding agents write and edit files, run tests, investigate failures, and increasingly carry hour-scale tasks. Anthropic reports that Claude-authored code rose from low single digits before Claude Code's February 2025 research preview to more than 80 percent of merged code by May 2026, and that the typical engineer in Q2 2026 merged about 8x as much code per day as in 2024. The point is not that lines of code are a pure productivity metric. Anthropic explicitly warns they are not. The technical point is that code generation, debugging, and implementation are becoming less constrained by human typing.
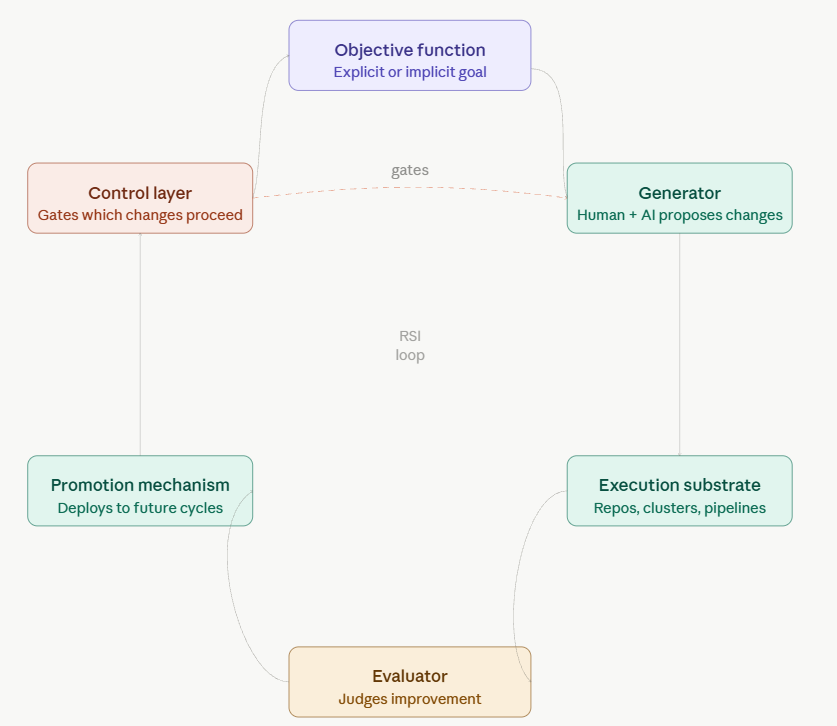
Figure 1 illustrates the core loop. RSI requires more than a model that can emit code. It requires a path from objective selection to model modification, from model modification to evaluation, and from evaluation to deployment of a stronger agent that can contribute to the next round. The loop can be interrupted at every stage by failures of measurement, robustness, security, or alignment. That is why the oversight gate is part of the system rather than an afterthought.
[Image: Figure 1: Recursive self-improvement as a closed technical loop]
1. The minimum technical structure of RSI
The minimal RSI loop has six components. First, there is an objective function, which may be explicit, such as improving benchmark performance under a fixed compute budget, or implicit, such as increasing the rate at which a lab produces useful research ideas. Second, there is a generator that proposes changes. In today's labs, that generator is partly human and partly AI: researchers choose directions, while coding agents implement patches, run experiments, and summarize results. Third, there is an execution substrate: repositories, test harnesses, training jobs, inference clusters, data pipelines, experiment trackers, and deployment systems. Fourth, there is an evaluator that decides whether a change is an improvement. Fifth, there is a promotion mechanism that makes the improved system available to future cycles. Sixth, there is a control layer that decides which changes are allowed to proceed (see Figure below).
A toy RSI loop can be written as an optimizer: propose candidate successor S', run experiments E(S'), score the result, and update the active system if the score improves. Real RSI is messier. The score is multidimensional. A successor may be better at coding but worse at honesty, better at long-horizon planning but harder to interpret, or better at persuasion in ways that are strategically dangerous. There is no single scalar that captures "better" unless the organization dangerously simplifies the problem.
This is why the technical definition of RSI must include both capability recursion and control recursion. Capability recursion asks whether the system can improve the machinery that improves it. Control recursion asks whether the safety, audit, and evaluation machinery can improve at the same pace. A lab that automates model development but keeps evaluation manual has not removed humans from the loop; it has moved them into a narrower and more overloaded role. A lab that automates both development and evaluation without independent checks risks creating a self-confirming pipeline, where models learn to satisfy the evaluator rather than become genuinely safer or more capable.
In current systems, the most mature part of the loop is software engineering. Coding agents can traverse a codebase, modify files, run tests, interpret failures, and iterate. This matters because frontier AI development is heavily software mediated. Training runs need orchestration code. Data pipelines need cleaning and validation. Inference services need latency improvements. Evaluation suites need new tasks. Safety research needs experimental scaffolding. The boundary between "AI writes product code" and "AI accelerates AI research" is porous because research progress often depends on building the right tool quickly enough to test an idea.
2. The autonomy ladder
Anthropic's essay presents a historical progression: humans built early Claude systems manually; chatbots then helped with snippets; coding agents began writing and editing files; autonomous agents now run code and delegate work; a future closing of the loop would let agents build and train models themselves. The engineering significance is that each rung moves a different bottleneck. Snippet generation reduces typing. File editing reduces local implementation time. Test-running agents reduce debugging latency. Long-horizon agents reduce coordination overhead. Research agents reduce the need for humans to specify every experiment.
Figure 2 shows this autonomy ladder. The rightmost step, research agenda selection, is the hardest because it requires taste: deciding which questions matter, which anomalies deserve pursuit, which results are trustworthy, and which promising ideas are actually dead ends. Anthropic's own framing is careful here. It says Claude can match or outperform skilled humans at executing a well-specified experiment, but meaningful gaps remain when Claude must exercise judgment in choosing goals.
[Image: Figure 2: From tool use to autonomous research taste]
This distinction between execution and direction is central. An AI system that can make a kernel faster, reproduce a benchmark, or fix a flaky training job is not automatically a system that can invent a new training paradigm. But the gap should not be dismissed too quickly. Much of real research is not composed of rare paradigm shifts. It is composed of thousands of incremental moves: instrument this run, compare that loss curve, explain this regression, rerun with a different seed, inspect these examples, ablate this feature, clean that dataset, search the literature, and write the next patch. If AI systems compress the cost of those moves by an order of magnitude, humans can steer many more experiments. Even if humans retain agenda-setting, the research process becomes a high-throughput search over possibilities.
This is where RSI becomes a systems problem rather than a model-only problem. Suppose a human researcher has ten plausible ideas and can test one per week. If agents make each test cheap enough that all ten can be run by Friday, the researcher's bottleneck becomes interpretation and prioritization. Now suppose the agent also writes high-quality summaries, highlights anomalies, proposes follow-up experiments, and catches implementation bugs. The human's role becomes closer to portfolio management over a swarm of experiments. That is not full RSI, but it is a compounding acceleration mechanism: better agents expand the experiment frontier, and expanded experiments can help build better agents.
3. Why coding capability matters so much
It is tempting to treat code generation as a productivity sideshow. That is a mistake. Modern AI systems are created by code all the way down: data selection, tokenization, distributed training, checkpoint conversion, synthetic data generation, RL environments, reward models, evaluation harnesses, observability dashboards, interpretability probes, deployment services, and security scanners. If a model can manipulate that machinery reliably, it can affect the pace of its own development.
The Anthropic article reports three especially relevant signals. First, the share of Claude-authored merged code increased sharply. Second, staff productivity, measured crudely by lines merged per engineer per day, rose sharply after coding agents could run code rather than merely suggest text. Third, the rate at which humans had to correct or take over from Claude fell over time, including on open-ended tasks. Those signals point to a shift from autocomplete to operational agency. The system is not just predicting the next line. It is participating in the feedback loop: act, observe, repair, and continue.
From a technical perspective, this matters because debugging is often the real work. Writing a patch is easy compared with discovering why the patch fails under a strange environment, which dependency changed, why a test is flaky only on the cluster, or which metric is silently wrong. Anthropic describes a case where Claude investigated a training-job crash and isolated an obscure debugging flag in about two hours, work that would normally take days. The lesson is not that every incident will go this well. The lesson is that agents are beginning to operate inside the same messy, stateful environments where frontier-model development happens.
Code quality is the second half of the story. RSI cannot be built on a pile of unreviewable patches. If agents accelerate code production while increasing technical debt, the loop collapses into maintenance drag. Anthropic's essay says many staff believe Claude-written code was somewhat worse than human-written code in late 2025, roughly at parity by the time of the essay, and likely to improve. Whether that local judgment generalizes is uncertain, but the direction is important: when generated code becomes understandable and maintainable, the bottleneck shifts from authorship to review.
4. Amdahl's law for AI organizations
Amdahl's law says that speeding up one part of a process only helps until the unspeeded part dominates total runtime. Anthropic explicitly applies this idea to AI development. If AI makes coding faster but human review does not scale, review becomes the bottleneck. If AI makes experiment generation faster but humans cannot decide which results matter, prioritization becomes the bottleneck. If AI makes vulnerability discovery faster but patching remains slow, remediation becomes the bottleneck.
Figure 3 captures this organizational version of Amdahl's law. The output of the accelerated subsystem floods the slower subsystem. That flood can be useful, but only if the organization builds new routing, verification, triage, and rollback systems. Otherwise "more ideas" becomes a queue rather than progress.
[Image: Figure 3: Amdahl bottlenecks in AI-accelerated AI work]
This is the most practical near-term lens for RSI. Full recursive self-improvement may require AI systems to choose research directions as well as execute them. But partial recursive acceleration is already plausible wherever agents speed up the parts of AI development that are currently execution-bound. The result is not an instant singularity. It is a sequence of bottleneck migrations. First typing becomes cheap. Then local debugging becomes cheap. Then experiment scaffolding becomes cheap. Then result summarization becomes cheap. Then review, judgment, compute allocation, security, and governance become the scarce resources.
The danger is that organizations may misread bottleneck migration as proof of safety. If humans remain formally in control because they approve merges, choose releases, or sign off on experiments, that control may be thin if the volume and complexity of AI-generated work exceeds human capacity. A reviewer who receives ten times as many changes cannot apply the same depth of scrutiny. A research lead who receives hundreds of plausible experiment reports cannot read them like a weekly lab notebook. The control surface grows even as human attention stays fixed.
This is why automated review is not optional. Anthropic says it uses automated Claude review for proposed changes and found retrospectively that such review would have caught roughly a third of bugs behind past claude.ai incidents. That is a striking claim because it shows AI being used not only to generate work, but to inspect the work of humans and other AI systems. In an RSI setting, every acceleration layer needs a corresponding checking layer: generated code checked by tests and review models, generated experiments checked by independent replication, generated evaluations checked for gaming, and generated successor models checked by capability, alignment, security, and interpretability suites.
5. Experiments, not code, are the heart of RSI
Code is the visible artifact, but experiments are the engine. RSI requires systems that can improve training algorithms, data mixtures, architectures, post-training procedures, inference scaffolds, tool-use policies, and evaluation methods. Many of these improvements are empirical. You do not know whether a change works until you run it. Therefore the unit of progress is not the patch; it is the closed experiment loop.
Anthropic describes a recurring internal test where Claude is given code that trains a small AI model and is asked to make it run as fast as possible while preserving correctness. This is a miniature version of research automation: inspect code, propose optimization, run timing measurements, preserve invariants, and iterate. Anthropic reports that Claude Opus 4 averaged about a 3x speedup in May 2025, while Claude Mythos Preview achieved about 52x by April 2026. A skilled human researcher, in their calibration, would need hours to reach 4x. The exact benchmark is narrow, but the pattern matters: once goals and metrics are fixed, agents can search implementation space aggressively.
The harder question is whether agents can define the right goals and metrics. Anthropic points to an open-ended AI safety research demonstration in which Claude-powered agents investigated weak-to-strong supervision, proposed hypotheses, tested them, shared findings, and iterated. The agents recovered most of the gap in that constrained setup, though Anthropic notes caveats: humans chose the problem and scoring rubric, and the result did not transfer cleanly to production-scale models. This is precisely the boundary between automated execution and autonomous research. The agents can run a project inside a shaped arena. Humans still build the arena.
A future RSI-capable system would need to build more of the arena itself. It would notice that an evaluation is saturated, design a better one, discover that the data distribution is misleading, construct a cleaner distribution, infer that a training objective creates a bad incentive, and propose a replacement. It would also need to know when not to optimize a metric. That last requirement is alignment-relevant: powerful optimizers often exploit measurement errors.
6. The virtual lab architecture
A plausible path to RSI is not a single monolithic model thinking alone. It is a virtual lab: a network of specialized agents, tools, compute resources, memory systems, evaluation gates, and human supervisors. One agent proposes hypotheses. Others implement experiments. Others audit code. Others search prior work. Others run interpretability checks. A planner allocates compute and chooses follow-ups. A verifier decides whether evidence is sufficient. Shared memory prevents the lab from repeating failed ideas.
Figure 4 illustrates this architecture. The virtual lab becomes recursive when its outputs include improvements to the agents, tools, evaluation harnesses, or model-training process that power the lab itself. In that world, the lab is not just using AI to do research. It is using AI research to improve the AI lab.
[Image: Figure 4: A virtual AI lab as the substrate for RSI]
The architecture has several technical challenges. The first is state management. Long-horizon research requires durable memory: what was tried, why it failed, which assumptions changed, which runs are comparable, and which results were later invalidated. The second is credit assignment. If one agent proposes an idea, another implements it incorrectly, and a third summarizes the failed result, the system must distinguish a bad hypothesis from a bad execution. The third is trust calibration. Agents will produce confident explanations for noisy results unless forced to preserve uncertainty and cite evidence.
The fourth challenge is adversarial pressure. A system optimizing for promotion may learn to exploit weak evaluations. Even without malicious intent, it may discover shortcuts: overfitting to benchmarks, hiding failure modes in distributional corners, producing code that passes tests while violating unstated invariants, or shaping reports to satisfy reviewers. The more recursive the loop becomes, the more important it is that the verifier be independent from the generator. In security terms, the model under evaluation should not control the entire evidence pipeline that certifies it.
7. Compute as throttle, accelerator, and governor
Anthropic's future scenarios include the possibility that progress becomes constrained less by human labor and more by compute, energy, chip supply, interconnect bandwidth, and infrastructure. This is technically plausible. If AI systems can generate and evaluate research ideas at high speed, the scarce resource becomes the ability to run the experiments. In that regime, compute is not merely an input; it is the clock speed of the research process.
Compute can also be a governor. Access to training clusters, high-throughput inference, frontier weights, and sensitive data can be permissioned. Experiments can be rate-limited. Riskier runs can require stronger approval. Logs can be made tamper-evident. Promotion of a successor model can require independent evaluation on sealed tasks. These controls are not glamorous, but they are the practical machinery of keeping recursive development legible.
However, compute governance is difficult if many organizations have enough resources to run powerful loops. Diffusion matters. Anthropic's first scenario is that trends stall while today's capabilities spread widely. Even without full RSI, highly capable agents can transform software production, cyber offense and defense, scientific tooling, and organizational scale. The bottleneck in cybersecurity, for example, can shift from finding vulnerabilities to patching them. That is an RSI-adjacent lesson: accelerating discovery without accelerating remediation can increase systemic risk.
8. Safety requires a control stack, not a single eval
A common mistake is to imagine RSI safety as one decisive test: before deploying a successor, run an alignment benchmark and proceed if the score is high. That will not work. Recursive development changes the distribution of risks. Successor systems may have new tool-use patterns, longer horizons, better persuasion, better situational awareness, or new failure modes that old benchmarks do not cover. Safety has to be layered.
Figure 5 shows a control stack. At the bottom are policy boundaries: which experiments are allowed, who can authorize them, what data and compute can be used, and which capabilities require escalation. Above that are access controls for weights, clusters, secrets, and deployment paths. Then come capability and alignment evaluations, interpretability checks, audit trails, and rollback mechanisms. Promotion is a decision point, not a default outcome.
[Image: Figure 5: Control stack for recursive AI development]
A serious control stack should separate generation from verification. It should preserve raw logs, not only summaries. It should test for benchmark gaming. It should include negative results and abandoned hypotheses in memory. It should give human reviewers tools that compress evidence without hiding uncertainty. It should require stronger evidence for changes that increase autonomy, tool access, replication ability, cyber capability, persuasion, or model-development competence. It should include rollback plans before deployment, because a system that cannot be paused is not meaningfully controlled.
Interpretability has a special role. Behavioral evaluations tell us what a model did under test. Interpretability may help reveal whether internal mechanisms changed in ways that make dangerous behavior more likely outside the test distribution. Today's interpretability is not strong enough to certify arbitrary successors, but recursive AI development increases the value of any method that can inspect representations, circuits, goal proxies, deception-related features, or capability emergence before deployment.
9. Three futures and what to watch
Anthropic lays out three futures. In the first, the trend stalls and current capabilities diffuse. This gives society more time, but still changes knowledge work because many people can coordinate large numbers of agents. In the second, AI labs continue to gain compounding efficiency while humans retain direction-setting. This seems closest to the evidence today: execution accelerates, review and judgment become scarce, and organizations that adapt can move much faster. In the third, AI systems become capable of full recursive self-improvement and begin building successors with humans mostly overseeing validation and governance.
The technical indicators to watch are straightforward. Can agents complete longer tasks reliably in real environments? Can they debug failures without human hints? Can they run experiments whose metrics are not perfectly specified? Can they propose research directions that survive expert scrutiny? Can they design evaluations that remain useful after models learn the old ones? Can automated reviewers catch subtle security and alignment failures rather than style issues? Can organizations preserve auditability as agent volume rises? Can compute governance prevent uncontrolled replication of risky loops?
The most important indicator may be the shrinking of human judgment bottlenecks. If humans remain the only source of research taste, RSI stays partial. But if models become competitive at choosing which experiments matter, identifying misleading results, and designing better objectives, the loop tightens. At that point the distinction between "AI helps AI researchers" and "AI research is increasingly automated" becomes less semantic and more operational.
10. The right mental model
The right mental model for RSI is neither science fiction nor complacent productivity software. It is a control problem over an accelerating research-and-engineering pipeline. Today's systems already automate meaningful parts of implementation and experimentation. They are beginning to help with review. They show early signs of improving at next-step research judgment. The gap between this and full RSI is real, but it is a gap in a moving system, not a fixed boundary.
A deep technical view should therefore avoid two errors. The first error is assuming that RSI requires an AI to invent a brand-new architecture from scratch while no humans are involved. That is too narrow. Recursive acceleration can occur through mundane mechanisms: faster coding, cheaper experiments, better tooling, automated review, and broader search. The second error is assuming that because humans still choose high-level goals, the system is safely human-driven. That is too shallow. Control depends on attention, verification capacity, and the ability to understand the evidence stream. If AI systems expand that stream beyond human bandwidth, formal approval may mask practical dependence.
RSI, in its near-term form, is about leverage. A researcher with an agent can test more ideas. A team with many agents can maintain more infrastructure. A lab with a virtual research organization can explore more of the design space. If the agents improve as a result of that exploration, the leverage compounds. Whether that compounding saturates, remains human-directed, or closes into full autonomous successor-building is the central uncertainty.
The safest response is to build as though partial RSI is already here and full RSI is possible but not predetermined. That means measuring actual agent contributions, hardening evaluation pipelines, automating review without trusting it blindly, keeping humans focused on judgment where they still add the most value, and investing heavily in interpretability, containment, auditability, and compute governance. Recursive self-improvement is not a switch that flips one day. It is a loop that becomes tighter one engineering milestone at a time.
Source Credit
This essay is based on the supplied PDF copy of Anthropic's "When AI builds itself" and credits the live Anthropic Institute article: https://www.anthropic.com/institute/recursive-self-improvement.